2022年大一下学期,必修课学了计算机编程语言Python最基础的几个章节,老师上课讲到“字典”这部分,觉得这个东西用途很大。
2023年年初到年底,ChatGPT诞生的一年间,我同时也有了笔译实践和口译实践译前准备堆积的大量语料和术语,都一并通过文档、表格形式,精确命名存储在U盘中。ChatGPT当时使用很麻烦,渠道很受限,当年的许多翻译任务仍然利用Deepl和有道翻译作为主力工具。
2024年,堆积的各种语料更多更杂了。
2025年DeepSeek诞生的时候很不好用,因此术语管理依然限于文件夹套文件夹、文档+文档。但随着这些资料越积越多和人工智能的迭代升级,随着深耕专业带来的实践量的攀升和对语言资产管理的精细化需求,随着我个人在电子文件管理方面的不断成熟,一个“人脑的语言资产管理理念+生成式人工智能助力+计算机编程语言”三合一的语言资产管理方式涌现在我脑海中。
当时,我不知道这个思考有没有实践落地和论文支撑。前不久,我注意到知网有关Python赋能翻译项目管理全流程的文献 。
我认为,虽然我的计算机编程一塌糊涂,但是完全可以积极拥抱生成式人工智能技术,利用我在电子材料管理方面的优势(技巧、逻辑等),通过巧妙的AI提示词设计,行成一个现有需求下足够使用的Python程序,并留有余地,可以不断更新,将来也可以借助人工智能或者人工进行修改。
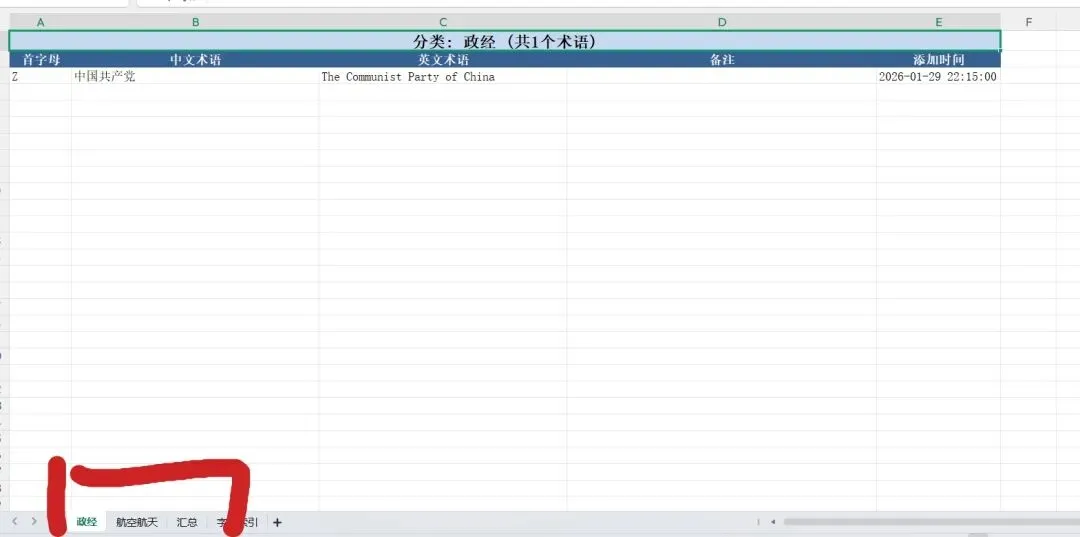
于是,可以随意添加、双向搜索、导出、备份的1.0版本诞生了,阐明了文科专业、外语专业也可以拥抱包括人工智能在内的各项技术的真理。不求最先使用、不求技术上的领先,但求动态契不断变化的术语管理需求(当然将来可能延伸到其他语言资产)


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
