 cover_controllable_ai_coding
cover_controllable_ai_coding对 Claude Code、Codex、Gemini CLI 这类命令行 AI 编程工具都适用
在讨论 AI 编程时,常见的问题往往集中在这些层面:
这些问题都很现实,但如果你真的把 AI 放进工程环境里跑一段时间,会发现它们只是表面现象。
真正棘手的是:你能不能把“会出什么错”列出来?
如果错误路径本身不可穷举,那任何“靠人盯着、靠经验判断”的控制方式,迟早会漏掉一次。
一、问题重述:AI 编程的核心风险是什么
在真实工程环境中,AI 的风险并不是某一个已知操作,例如:
这类风险其实比较好处理,因为你可以明确拦截。
真正不可控的是:
AI 的错误路径是“组合”出来的,没法穷举。
 image-659
image-659即使你今天拦住了所有你能想到的危险操作,明天依然可能出现一个你没预料到的组合拳。
所以我更愿意把问题说得直白一点:只要安全性依赖“我每次都能判断对”,那就不算工程上可控。
二、设计目标:在“不可枚举风险”下实现可控
因此,问题需要被重新定义。
我们真正需要解决的不是:
❌ 如何让 AI 不犯错
而是:
✅ 当 AI 犯错时,是否仍然安全
换句话说:
控制的对象不应该是“行为”,而应该是“错误的影响范围”。
这是一个典型的系统设计问题,而不是 AI 能力问题。
三、思路:把“兜底”写进结构里
在工程上,解决不可枚举风险的经典做法只有一种:
通过结构设计,限制最坏结果。
在 AI 编程场景中,这个结构可以拆为两层:
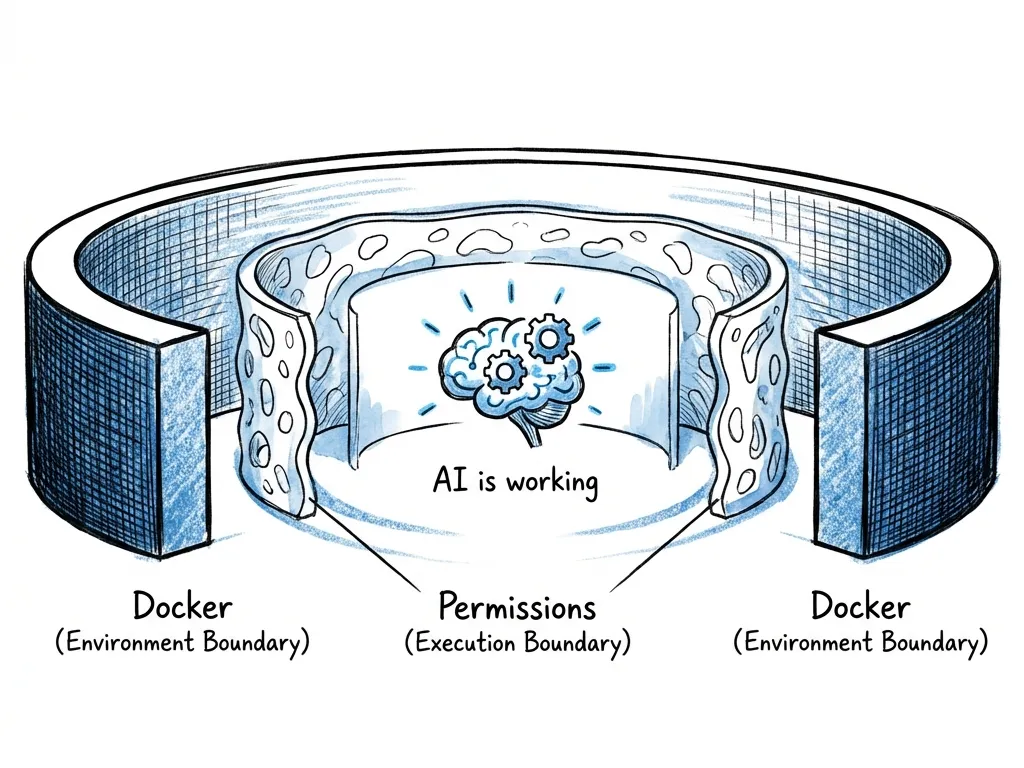 two_layers_defense
two_layers_defense
只要这两层成立,AI 就可以在边界内“自由探索”,而不会对真实系统产生不可逆影响。
我自己用的方案:Docker 沙箱 + 权限规则
一句话总结:把 Claude Code 放进 Docker 里跑,只挂载项目目录;再用权限规则把高风险命令卡住。
宿主机(Host)「当前电脑」├─ 系统文件 /Users /Applications /etc│ └─ Claude Code ❌ 无访问权限│├─ ~/.ssh(SSH 私钥)│ └─ Claude Code ❌ 无访问权限│├─ Docker Daemon & 其它容器│ └─ Claude Code ❌ 无访问权限(无 docker.sock)│├─ 项目目录(挂载到 docker「docker 沙箱」)「要访问的项目文件夹,也就是 claude code 写代码的文件夹」│ └─ /Users/Desktop/项目文件夹│ ├─ Claude Code ✅ 读文件│ ├─ Claude Code ✅ 写文件│ ├─ Claude Code ✅ 删除文件│ └─ Claude Code ✅ 执行命令(受 permissions 控制)│└─ 网络 ├─ 智谱 / Claude API │ └─ Claude Code ✅ 可访问 └─ 其它公网地址 └─ Claude Code ✅ 可访问(未做额外限制)
四、第一层控制:运行环境边界(Docker 沙箱)
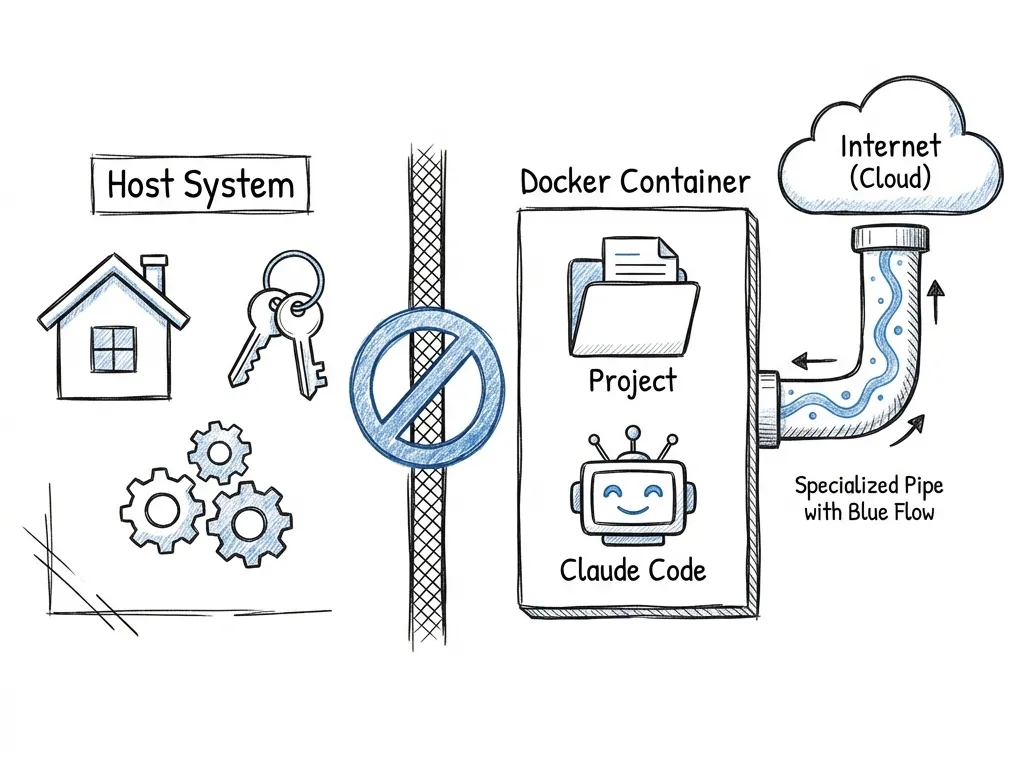 docker_vs_host_diagram
docker_vs_host_diagram4.1 目标
- AI 不具备任何隐式信任资产(如 SSH key)
4.2 实际运行方式
Claude Code 并不直接运行在宿主机,而是固定运行在 Docker 容器中:
docker run --rm -it \ -v "$(pwd)":/workspace \ -w /workspace \ --cap-drop ALL \ -e ANTHROPIC_AUTH_TOKEN=... \ -e ANTHROPIC_BASE_URL=https://open.bigmodel.cn/api/anthropic \ node:22 \ npx @anthropic-ai/claude-code
4.3 这层结构性带来的效果
- 宿主机的
$HOME、系统配置、SSH 目录不可见
在该环境中执行:
ls -la ~/.ssh/
结果只包含 known_hosts,不存在任何私钥。
结论:
即使 AI 尝试执行 git push,在物理层面也很难完成认证。但 add 和 commit 依然可以正常用,版本管理不会受影响。
这不是策略,而是环境事实。
五、第二层控制:执行权限边界(Claude Code 权限模型)
Docker 解决的是“在哪里运行”,但仍需要解决一个问题:
在这个世界里,它能做哪些事?
Claude Code 原生支持基于命令粒度的权限模型:
5.1 实际使用策略
在项目内固定维护:
.claude/settings.json
策略原则非常明确:
例如:
5.2 关键点
这并不是“限制 AI 的能力”,而是把系统边界写成规则,而不是放在人的脑子里。
六、一个重要结果:控制不再依赖“人工注意力”
在两层结构同时存在的情况下,会出现一个显著变化:
人不再需要持续盯着 AI 的每一步。
原因很简单:
这时,AI 的行为从“需要被盯着”变成了“可以放手去跑,但你依然能兜住”的自动化执行单元。
七、为什么这套方式更好
因为这套方法并不依赖于:
它解决的是一个长期成立的问题:在不可枚举风险下,如何把系统做得“即使出错也不至于崩”。
这一原则同样适用于:
八、结论:什么是“可控的 AI 编程”
可控的 AI 编程,不仅仅是:
而是:
让错误即使发生,也只能发生在一个被精确限制、可回滚的范围内。
 relaxed_supervision
relaxed_supervision在这种结构下,你可以让 Claude Code 放手干活,因为它“最多把项目目录搞乱”,而不是把整台机器搞乱。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
