从GRPO到Dr. GRPO:两行代码消除RL中的偏差
- 2026-07-02 17:52:23
★原文链接:https://zhuanlan.zhihu.com/p/1991211084418412751
作者:魔法学院的Chilia
在这篇文章中,我们将介绍PPO算法的一个简化改进版本GRPO,并且介绍GRPO的改进版Dr. GRPO(之后还会有若干针对GRPO公式的改进,这些我们下次再说)。
我们开始今天的内容吧~
本文共5303字,预计阅读时间30分钟。
0x01. GRPO
“群体让他们对自己的利益形成了或许有失偏颇但至少十分明确的看法,并让他们意识到了自己的力量。” ——《乌合之众》,古斯塔夫·勒庞
论文🔗: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models,https://arxiv.org/pdf/2402.03300
看过我们上一次介绍PPO的同学,大家都觉得PPO里面那块最难呢?
反正对于我来说,我是觉得GAE和critic model那里最难。GAE是用来估计Advantage的,因为我们其实并不知道Advantage,必须要用一种方式来估计它。在GAE的公式里又有 ,也就是value,而这个value我们也是不知道的,必须用一个新的模型——Critic Model来预测。而Critic Model的更新目标又与GAE估计出来的Advantage有关。上次的文章里,我们分析了这个循环的具体过程,以及为什么这并不是一个死循环(因为每次都引入了新的信息——reward)。
然而:
从系统的角度来讲,由于Critic Model的大小通常和我们要优化的Actor Model相当,所以内存消耗和训练复杂度还是非常高的。 从算法的角度来讲,对于一个完整的生成序列(在LLM中,就是一个response),只有最后一个 token 是有reward分数的,而Advantage/value是每个token都有的。因此,训练一个能在每个 token 上都准确估计的价值函数其实是非常困难的。
因此,在GRPO中我们不需要用GAE来估计advantage,当然也就不需要Critic Model。
我们先放GRPO的公式,以便让大家有一个整体的认知,然后我们会对公式中的每个组件进行详细的介绍。
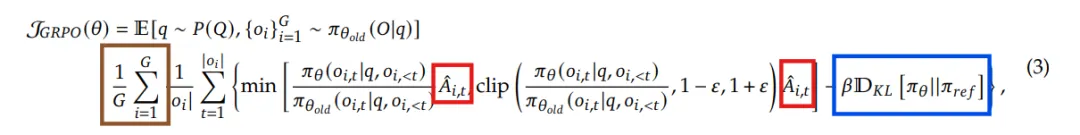
对比之前的PPO公式:
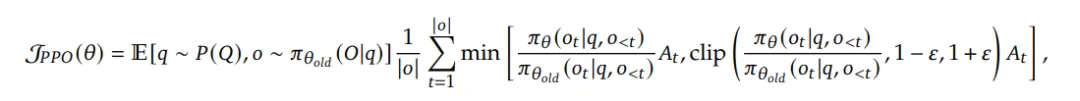
下面,我们来分析GRPO与PPO的不同点。
(1)改进点1:如何估计Advantage?
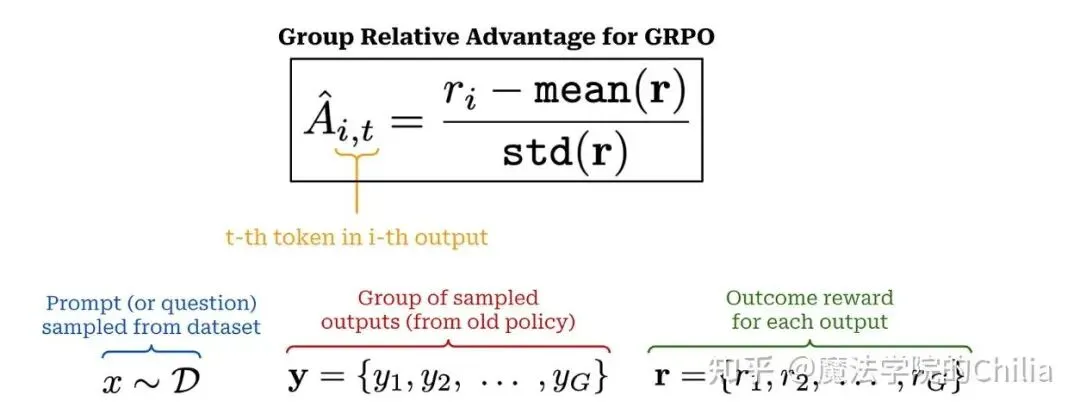
GRPO提出了一种更简单的Advantage估计方法。具体而言,GRPO通过对每个prompt采样 次,得到个completion,构成一个“group”,然后用这个group中的平均情况当作baseline。这样,我们直接就算出来了Advantage,而不需要用Critic Model。
对于组内的第 个completion,我们计算它对应的reward对于组内所有reward中的标准化值(也就是减去组平均,除以标准差),然后把这个当成的advantage。对于第 个completion的所有token,它们的advantage全部都是这个reward的标准化值
之前的PPO算法通常每个prompt仅采样一个结果,但是GRPO必须采样多个结果,而且必须足够多(如每个问题都sample 64个response),才能获得稳定的策略梯度估计。
(2)改进点2:如何引入KL penalty?
上一次我们在讲PPO的时候讲到,PPO中的KL penalty是直接加在reward上面的(这个reward用于GAE的计算,估计advantage):
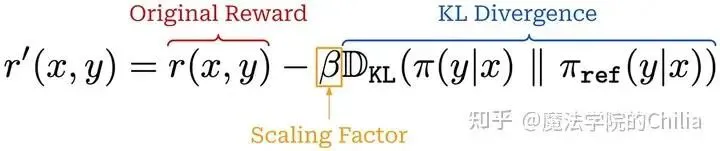
而GRPO的KL penalty是作用在loss上的,这样做的目的是不要让计算 变得很复杂:
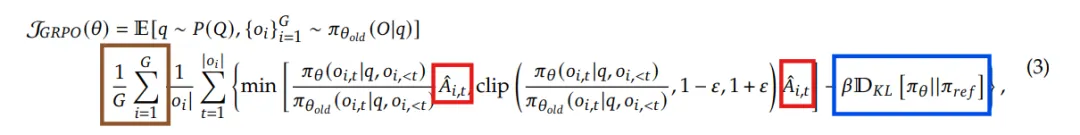
(3)改进点3:使用过程监督reward
准确来说,这并不能算是GRPO的改进点,因为过程监督本身是和算法无关的,对于其他的RL算法也可以选用过程监督/结果监督。
所谓结果监督,就是每个模型的reponse仅提供一个奖励信号(正确/非正确,或者是数值得分),但是这在复杂任务中可能既不够充分,也难以高效地指导学习。比如,虽然一道题的结果错了,但是也未必说明它之前的所有推理过程都毫无可取之处。可能推理过程一开始是对的,到后面某一步之后才发生了错误。
过程监督(process supervision) 就是把推理分成若干个步骤,每一步推理结束时都提供一个奖励。具体而言,给定一个问题 和采样的 个输出 ,我们使用一个过程奖励模型(process reward model, PRM)对每个输出中的每一步打分,从而得到对应的奖励序列:
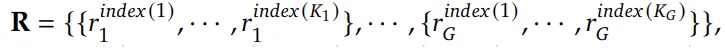
其中 表示第 步推理结束时对应的 token 位置, 是第 个输出中包含的总推理步数。
之后,我们也需要进行归一化处理——用整个group内的所有步骤奖励的均值和标准差进行归一化:
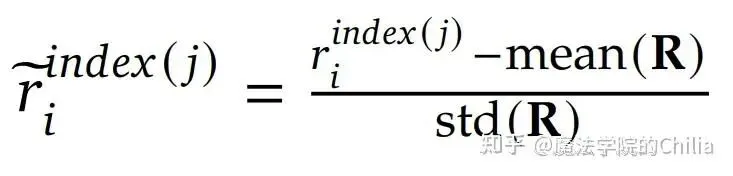
每个token的advantage值就是它之后推理路径后续步骤的归一化奖励之和:
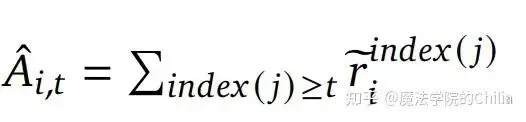
但是,其实要想把过程监督做好还是相当困难的,主要难点在于训练一个足够好的PRM模型来对过程进行打分。
0x02. Dr. GRPO
“K. 相信,自己应该是闯入了某处正在举行集会的现场:形形色色的一大群人挤在这里,没有任何人在意那个刚刚进来的家伙。”——《审判》,卡夫卡
论文链接🔗:https://arxiv.org/pdf/2503.20783,Understanding R1-Zero-Like Training: A Critical Perspective

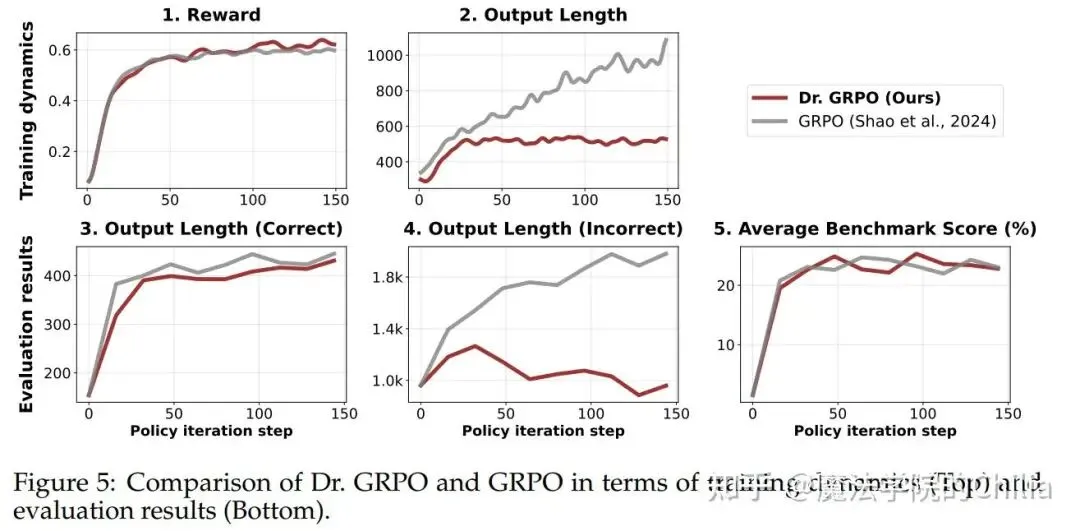
(1)震惊!RL之后推理长度的增加竟然是因为GRPO的固有偏差?
在RL的训练过程中,我们经常观察到模型生成的回答长度持续增长,这个现象常被认为是模型正在发展出更高级的推理能力。但是分析GRPO的目标函数之后,我们可以从另一个角度来理解这个事情——回答长度增长也可能源于 GRPO目标函数本身存在的bias。
我们可以从两个角度来理解这个bias:
(a) 长度偏差(Response-level length bias)
这种偏差源于对 (即第 个回答的长度)进行归一化。就是这里:

对于正优势值( ,表示回答正确),较短的回答会获得更大的梯度更新(分母小),从而使得模型倾向于在正确回答中追求简洁; 而对于负优势值( ,表示回答错误),由于较长回答的 更大,其惩罚被稀释了(分母大),进而导致模型在错误回答中更倾向于生成更长的内容。
如下面这张图所示,

(GRPO 中的实际有效的优势值 其实相当于对无偏优势值 进行了重加权。具体重加权的方式就是除以和 (即回答长度)。也就是这个操作引入了两个偏差。)
看图中的橙色箭头,向上的箭头表示正优势值,向下的箭头则表示负优势值。箭头的长短代表了数值的大小。可以看到对于长的回复,这个advantage都被稀释了。
(b)难度偏差(Question-level difficulty bias)
这种偏差源于在计算advantage的时候除以标准差 。对于标准差较低的问题(就是那些过于简单或过于困难的问题,其奖励几乎全为1或全为0),因此时会被赋予更高的权重。

尽管优势值归一化是强化学习中的常见技巧,但通常是在整个batch上进行计算的。相比之下,GRPO 在每个问题内部进行归一化,导致不同问题获得了不同的权重,从而在优化过程中引入了问题难度的偏差。
(2)Dr. GRPO
Dr. GRPO(Group Relative Policy Optimization Done Right)的实现就是把之前我们说的引入两个bias的组件去掉(也就是下图红色的部分):

从效果上看,虽然Dr. GRPO在得分上并没有明显升高,但是在长度上的变化是很明显的:GRPO会助长错误的回答变得越来越长,而Dr.GRPO并不会。因此Dr. GRPO提升了token efficiency.
(3)代码实现
(a) GRPO代码(OpenRLHF版本):
下面的代码来自OpenRLHF框架:
https://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/models/loss.pyhttps://github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/models/utils.py
def masked_mean(tensor: torch.Tensor, mask: Optional[torch.Tensor], dim: int = None) -> torch.Tensor:return (tensor * mask).sum(dim=dim) / mask.sum(dim=dim)loss = masked_mean(loss, action_mask, dim=-1).mean() ###per-response length normalization我们来逐行分析这段代码,并分析长度偏差是在哪里引入的。
首先, loss和action的形状都是[batch_size, seq_len]。loss * action_mask的形状仍然是[batch_size, seq_len],这一步的目的是将无效token(action_mask=0)被置为0,有效token保留原始值。(loss * action_mask).sum(dim=-1)在最后一个维度(也就是seq_len这个维度)求和,得到了每个样本所有有效token的总损失。形状是[batch_size]。action_mask.sum(dim=-1)也是在最后一个维度,即在seq_len维度求和,得到了每个样本的有效token数量(即响应长度)。形状是[batch_size]。(loss * action_mask).sum(dim=-1) / action_mask.sum(dim=-1): 也就是这个除法操作引入了长度bias, 因为对于每个token,都它的权重其实都除以了响应长度,导致在较长序列中的token权重被稀释。形状是[batch_size]。.mean()的计算:对batch中每个样本的平均损失求平均,也就是整个batch的平均平均损失,是一个标量。
(b) GRPO实现(verl 版本)
def masked_mean(tensor: torch.Tensor, mask: Optional[torch.Tensor], dim: int = None) -> torch.Tensor:return (tensor * mask).sum(dim=dim) / mask.sum(dim=dim)loss = masked_mean(loss, action_mask, dim=None) ###per-batch length normalization在verl版本中,相比OpenRLHF只是将 dim=1 变成了 dim=None 。
loss * action_mask的形状仍然是[batch_size, seq_len](loss * action_mask).sum(dim=None)对全张量的所有元素求和,得到了整个batch内所有有效token的总损失。这是一个标量。action_mask.sum(dim=None)也是对全张量求和,得到了所有有效 token 的数量,这是一个标量。(loss * action_mask).sum(dim=None) / action_mask.sum(dim=None): batch内的总损失 / batch内有效 token 数,代表整个 batch 的平均损失
相比于OpenRLHF版本,其实Verl版本实现的长度偏差已经是明显降低了,因为它的权重并不是除以每个序列长度,而是除以了整体batch的token数量。
(c) Dr. GRPO的实现
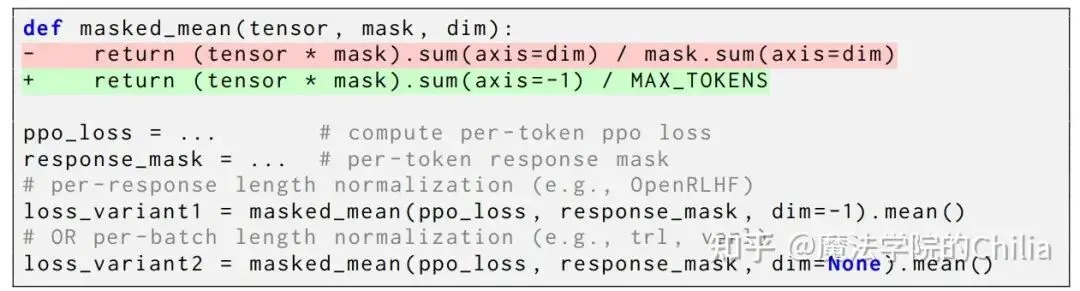
Dr. GRPO的实现则是完全没有长度偏差的,所有token在其中的贡献是一样的:
loss * action_mask的形状是[batch_size, seq_len](loss * action_mask).sum(dim=-1)在最后一个维度(也就是seq_len这个维度)求和,得到了每个样本所有有效token的总损失。形状是[batch_size]。Dr. GRPO除以的分母是一个常数 MAX_TOKENS, 因此无论是长、短序列,它们除以的值都是完全一样的,因此每个token对于整个loss的贡献权重是一样的。
本文参考
https://cameronrwolfe.substack.com

