大家好,我是木木。
今天给大家分享一个轻巧的 Python 库,pysolr。
pysolr
pysolr 是一个面向 Apache Solr 的轻量 Python 客户端。它提供了搜索、添加文档、删除文档、提交、更多相似查询和 term suggest 等常用能力,适合已经使用 Solr 的项目把 Python 服务接到搜索集群上。它的定位很清楚:不试图替你设计搜索系统,而是把 HTTP 请求、参数、JSON 文档和错误处理封装得顺手一些。用它时最重要的是把查询参数、超时、提交策略和批量写入边界控制好。
项目地址:https://github.com/django-haystack/pysolr
官方文档:https://pysolr.readthedocs.io/
三大特点
接口轻量
围绕 Solr HTTP API 做薄封装,学习成本低,排查也直接。
功能集中
覆盖 search、add、delete、commit 等常见 Solr 客户端动作。
适合集成
很适合 Django、脚本和后台任务把数据写入或查询 Solr。
最佳实践
安装方式:pip install pysolr。
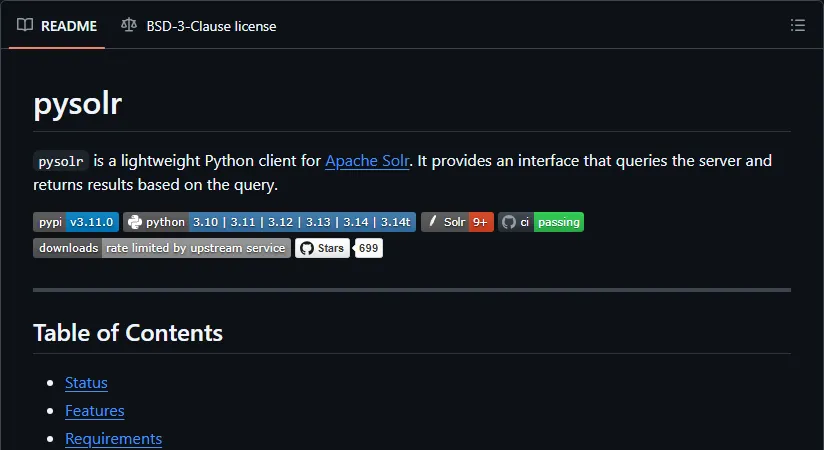
第一段代码解决的问题是:创建 Solr 客户端对象,确认 select 和 update endpoint 的拼接结果。示例只构造 URL,不访问真实 Solr 服务。
importwarningswarnings.filterwarnings("ignore")importpysolrfromimportlib.metadataimportversionsolr=pysolr.Solr("http://localhost:8983/solr/articles",timeout=2,always_commit=False)print("package:",version("pysolr"))print("select url:",solr._create_full_url("select"))print("update url:",solr._create_full_url("update/json"))
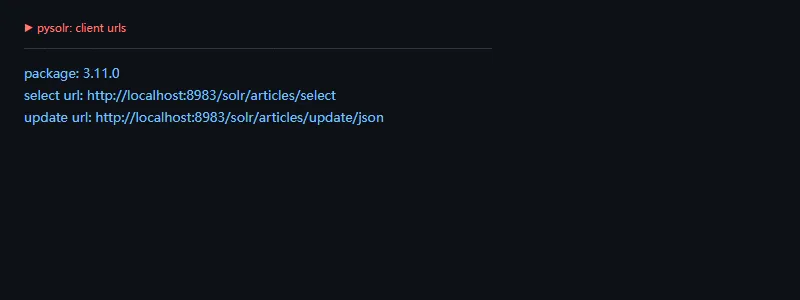
第二段代码解决的问题是:把搜索条件组织成明确的参数字典,便于日志记录和测试。
fromurllib.parseimporturlencodeparams={"q":"title:python","fq":"published:true","rows":5,"sort":"created_at desc",}print("params:",params)print("query string:",urlencode(params))
环境与版本信息
本文示例使用 Python 3.11.0,pysolr 3.11.0。示例只构造 URL、查询参数和文档 payload,不连接真实 Solr 服务。
高级功能
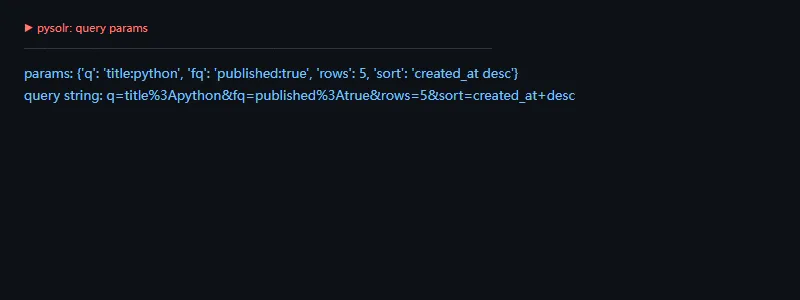
进阶一点看写入文档前的 payload。Solr 写入通常是批量任务,最好先在本地把文档字段整理清楚,再交给客户端发送。这样可以尽早发现字段缺失、类型不一致和空值问题。
importwarningswarnings.filterwarnings("ignore")importpysolrsolr=pysolr.Solr("http://localhost:8983/solr/articles",timeout=2,always_commit=False)doc={"id":"a1","title":"Python cache","tags":["python","search"]}clean=solr._build_json_doc(doc)print("id:",clean["id"])print("fields:",sorted(clean.keys()))print("tags:",clean["tags"])
适用场景
适合 Python 服务接入 Solr,做全文搜索、内容索引、后台批量写入、管理脚本和轻量搜索接口封装。
不适用场景
不适合没有 Solr 集群的小型本地搜索、需要复杂搜索平台治理、或希望完全隐藏搜索引擎细节的业务系统。
上线检查
- 给客户端设置合理 timeout,避免 Solr 慢查询阻塞业务线程。
- 批量 add 后明确 commit 策略,不要把每条写入都强制提交。
- 查询参数要有日志和测试样例,避免线上因为字段变更静默无结果。
总结
pysolr 的优点是轻。它适合已经选定 Solr 的项目,把 Python 侧的查询和写入代码收得更干净。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
