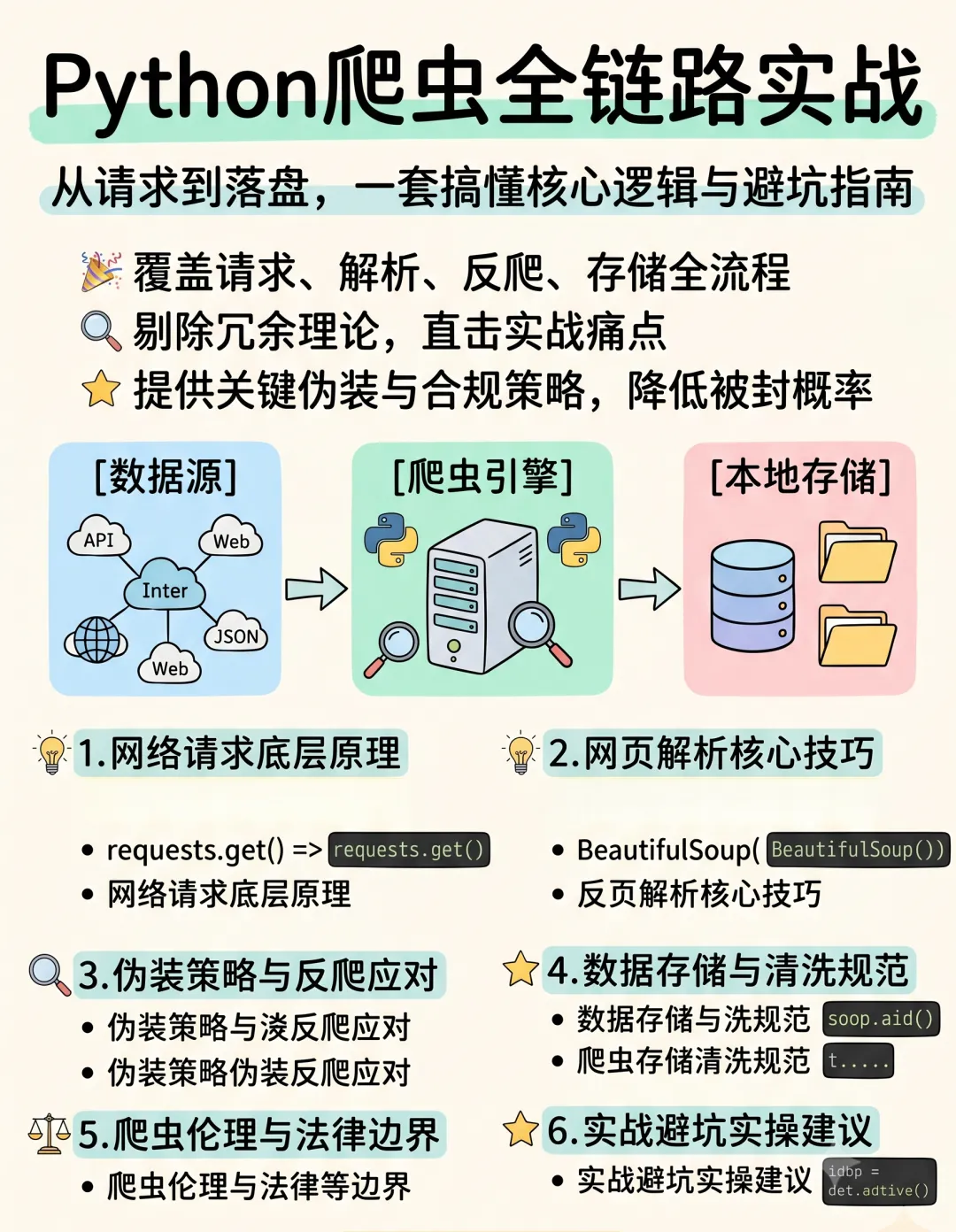
一、什么是爬虫?
爬虫是自动抓取互联网信息的程序,模拟浏览器请求网页,解析HTML内容,提取结构化数据并保存。
二、Python爬虫常用库
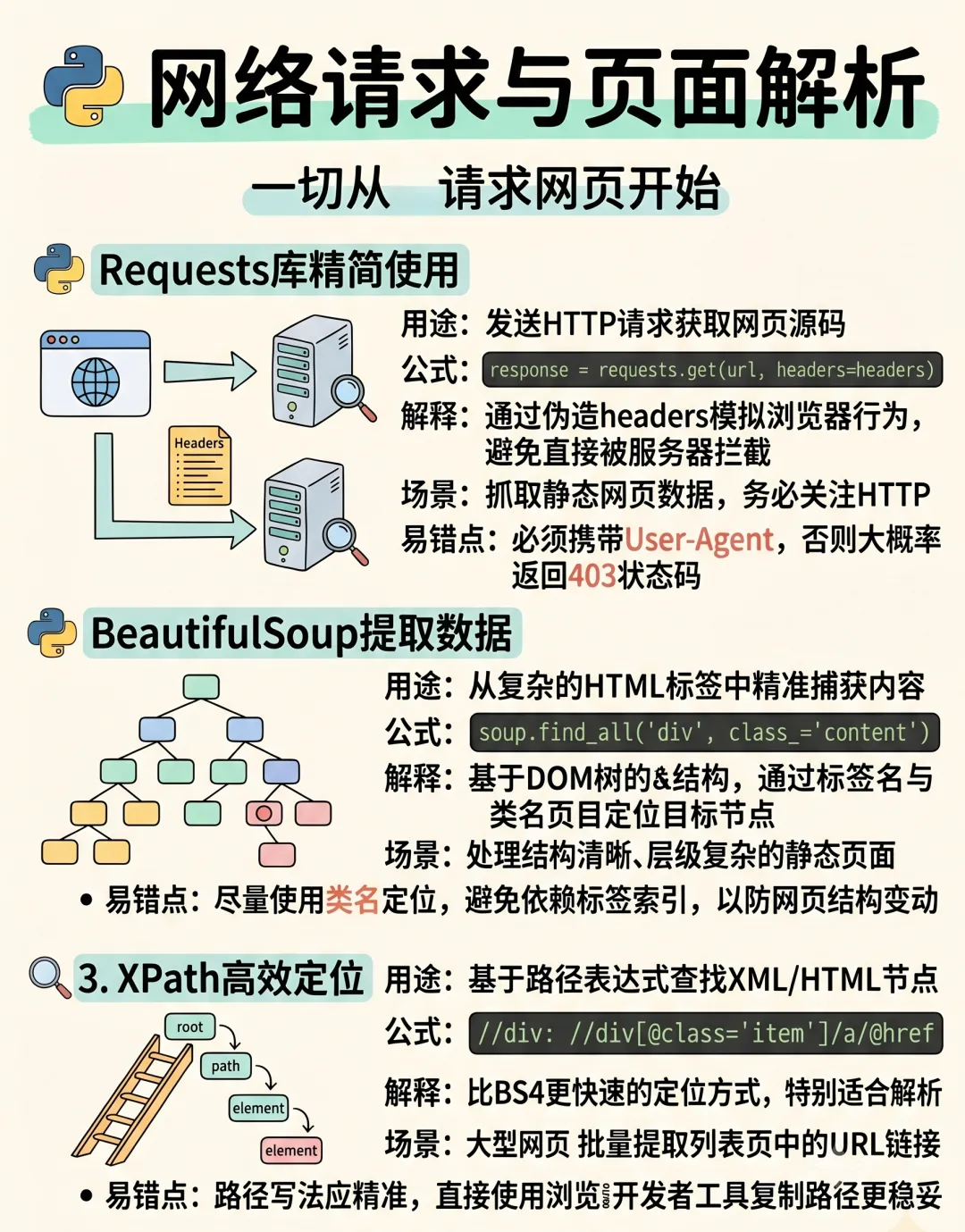
HTTP请求
requests 发送GET/POST请求,最基础的请求库
httpx 支持异步,速度快
aiohttp 异步HTTP客户端/服务端
HTML解析
BeautifulSoup4 新手友好,API简单
lxml 性能好,支持XPath
parsel Scrapy内置,支持CSS和XPath
动态渲染
Selenium 模拟真实浏览器(Chrome/Firefox)
Playwright 微软出品,比Selenium更现代
Pyppeteer Puppeteer的Python实现
爬虫框架
Scrapy 最成熟的爬虫框架,自带去重、调度、中间件
Crawlee 新兴框架,支持JavaScript渲染
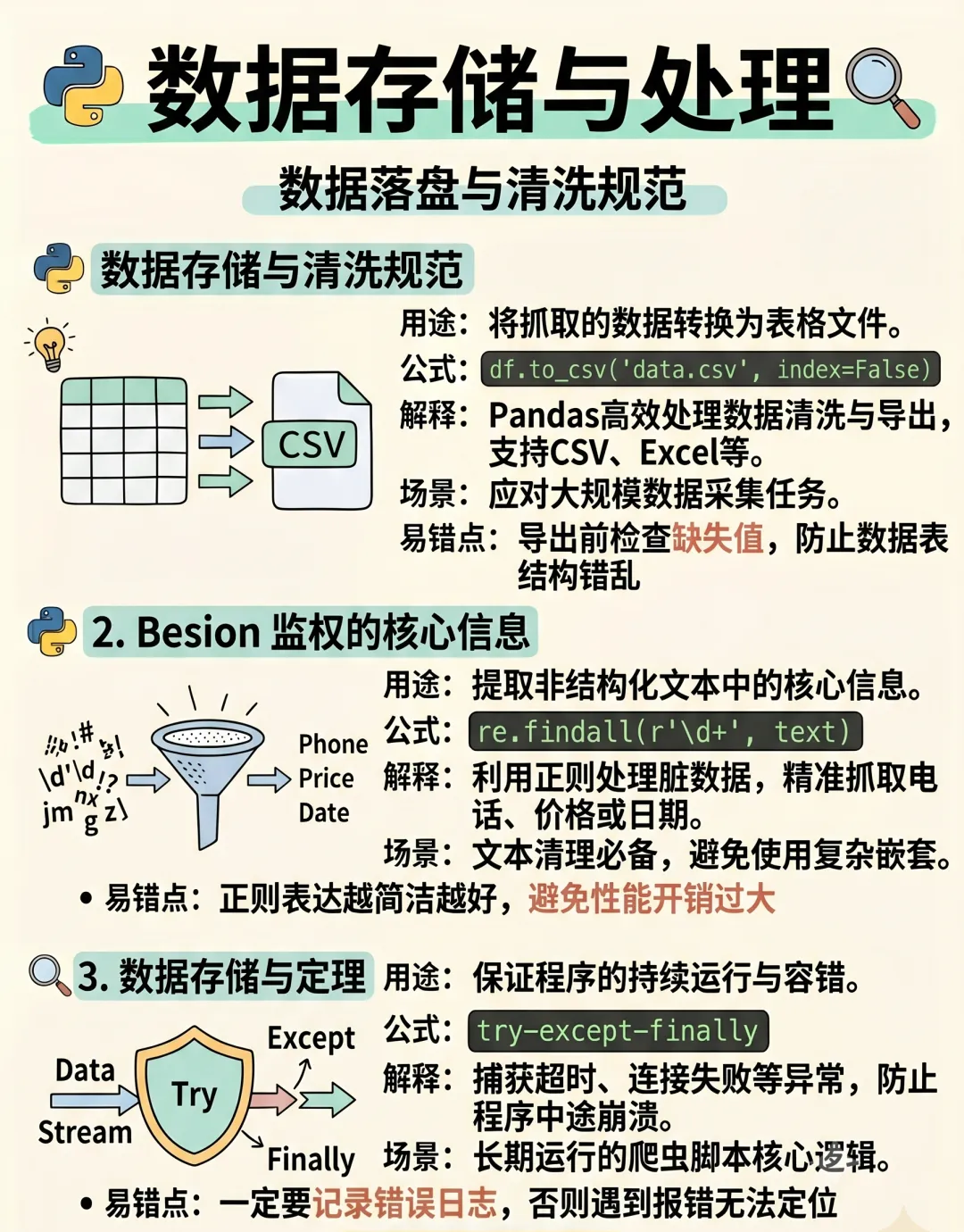
数据存储
pandas 导出CSV/Excel
SQLAlchemy ORM,存储到数据库
openpyxl 写入Excel
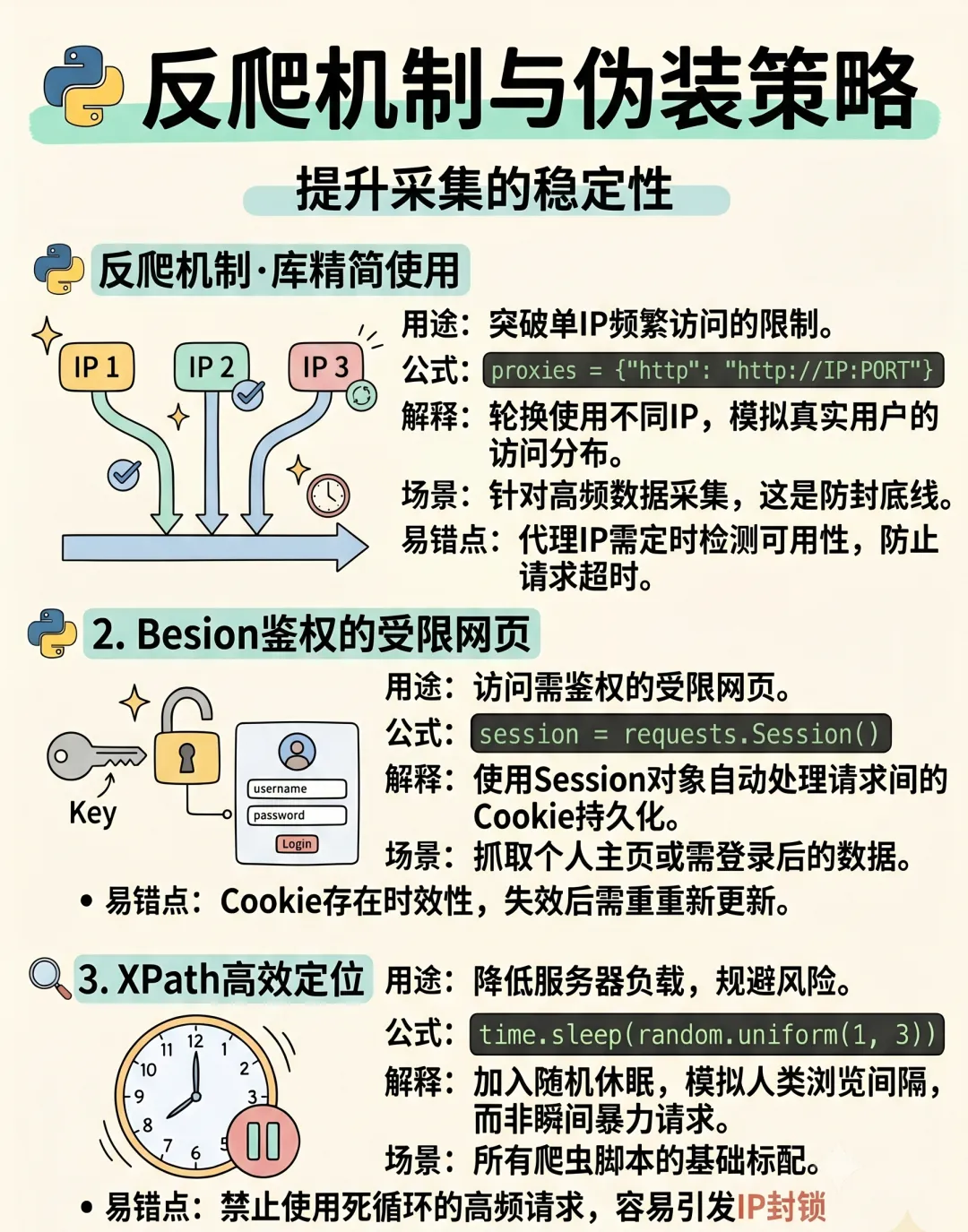
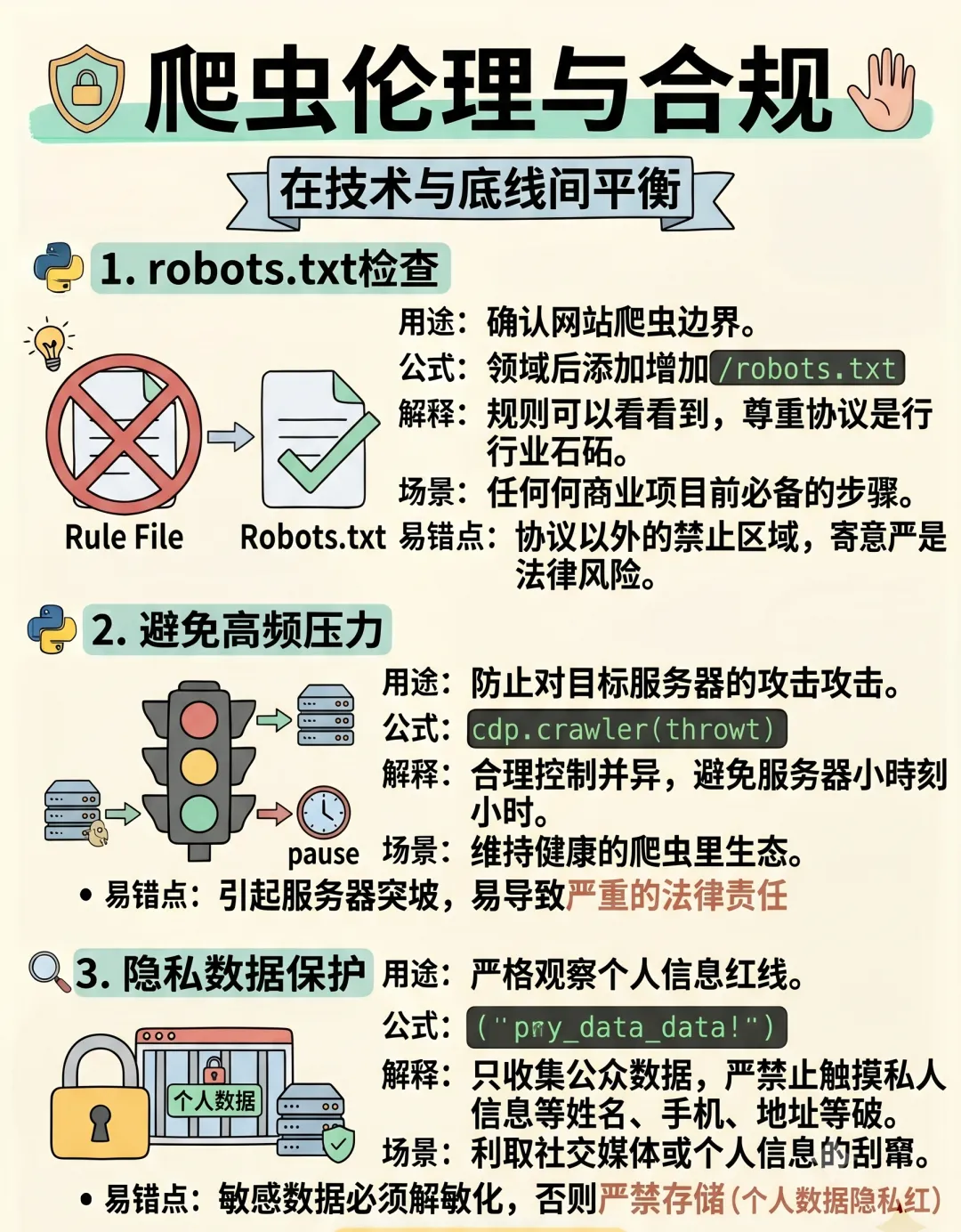
三、应对反爬策略
1.User-Agent检测:随机切换UA,使用fake_useragent库
2.IP封禁:代理IP池,使用requests的proxies参数
3.请求频率限制:加随机延时:time.sleep(random.uniform(1,3))
4.验证码:打码平台(超级鹰)、OCR识别
5.动态Token:逆向JS,分析Token生成逻辑
6.数据加密:逆向加密算法,模拟加密过程
四、推荐学习路径
第一阶段(2周):requests + BeautifulSoup,爬取静态网页
第二阶段(2周):Selenium,处理动态加载
第三阶段(2周):Scrapy,学习框架、中间件、Pipeline
第四阶段(持续):应对反爬,学习抓包、JS逆向、代理池
静态练习:豆瓣、知乎、人民网
动态练习:今日头条、微博(需登录)
反爬练习:淘宝、京东、小红书
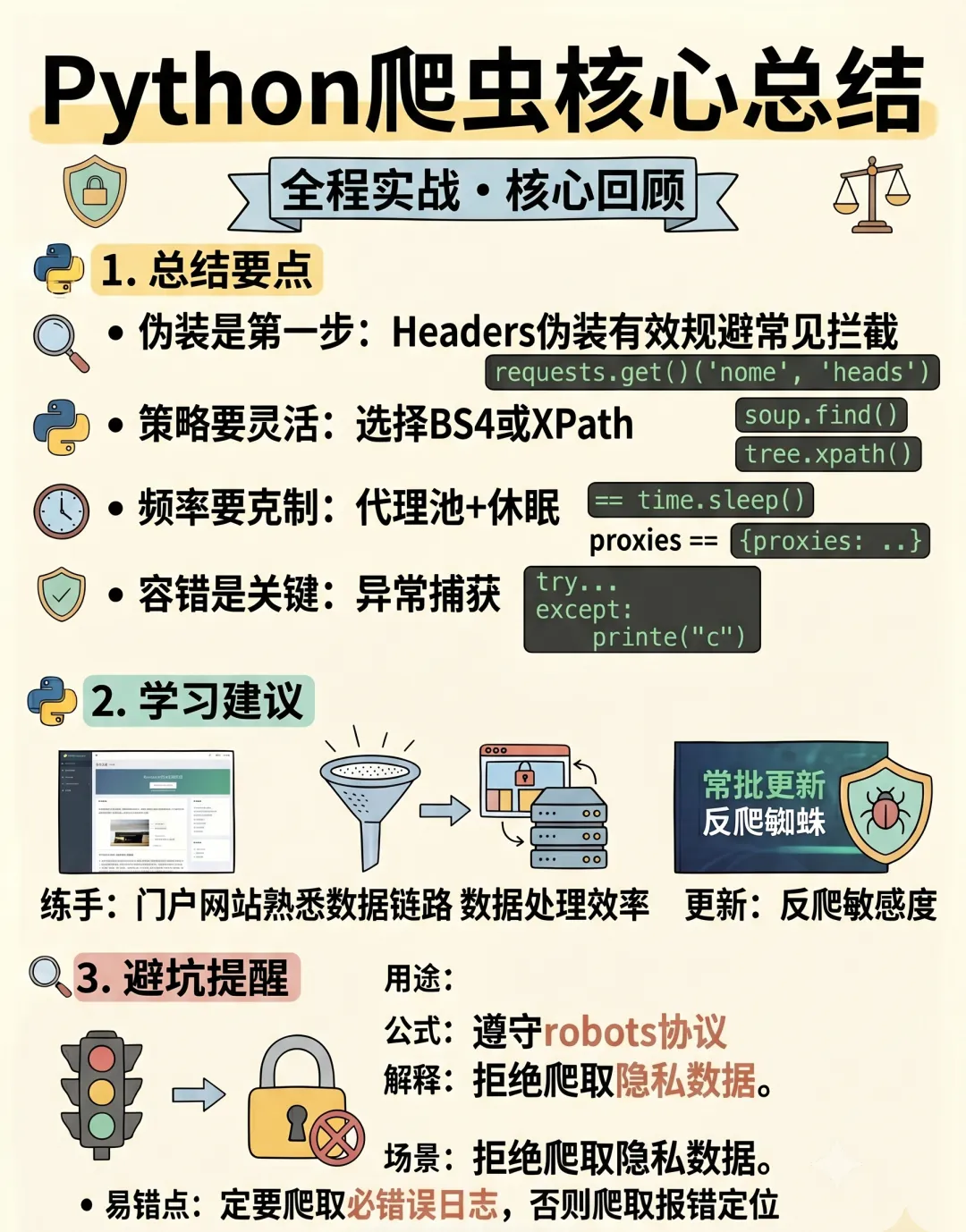
总结
核心库:requests + BeautifulSoup 入门;Selenium 攻克动态;Scrapy 工业化
关键能力:能分析请求、能解析HTML、能应对反爬
底线:遵守robots.txt,尊重版权,别把服务器爬崩
进阶方向:JS逆向、App爬虫、分布式爬虫、爬虫管理平台
爬虫是数据采集的起点,掌握它,你就拥有了自己获取数据的能力。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
