由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/3beb4a55ad9f48d7ae5da9cc7eb79d68
附件中的文献《生产性服务业集聚何以赋能技术扩散》中提到了城市的生产性服务业专业化集聚指标和多样化集聚指标,今天的课程中我们将会讲解如何使用 Python 语言根据城市统计年鉴数据来测算这两个指标。
城市统计年鉴数据在这里:
1999~2025 年中国城市统计年鉴面板数据整理结果: https://rstata.duanshu.com/#/brief/course/c6b0aaf3bcba494faadbacacb012dcef
这里选择的是 2017~2019 年的样本作为演示使用。也就是附件中的 城市统计年鉴样本数据.dta。
一、指标来源与计算公式
1.1 专业化集聚指数 SP(公式4)
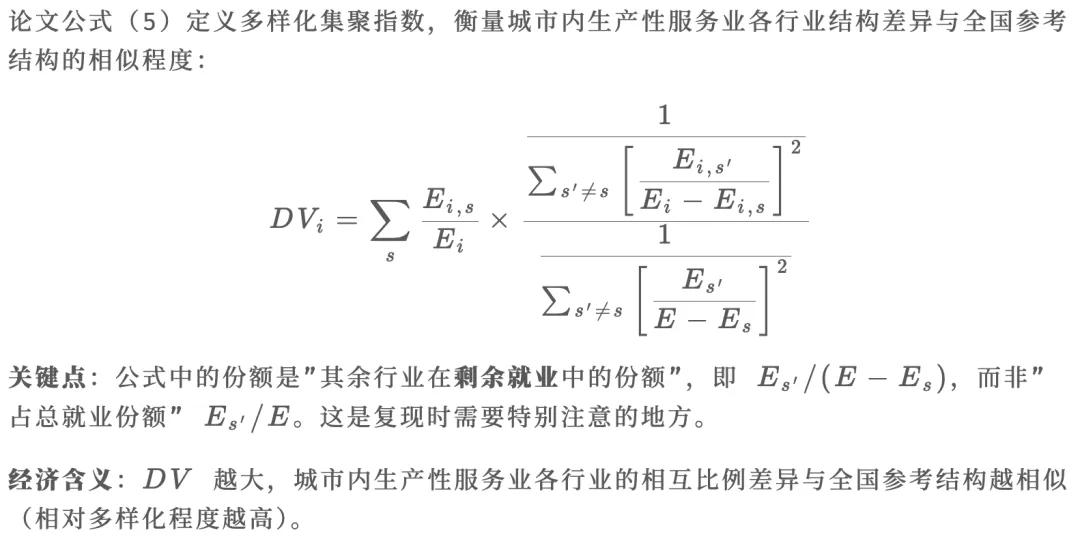
1.2 多样化集聚指数 DV(公式5)
二、数据与变量说明
2.1 数据来源
城市统计年鉴数据在这里:
1999~2025 年中国城市统计年鉴面板数据整理结果: https://rstata.duanshu.com/#/brief/course/c6b0aaf3bcba494faadbacacb012dcef
这里选择的是 2017~2019 年的样本作为演示使用。也就是附件中的 城市统计年鉴样本数据.dta。
由于计算所需的变量主要集中在 2003~2019 年,所以完整数据仅可计算得到 2003~2019 年的。
2.2 生产性服务业行业界定
参考 Ke et al.(2014)和韩峰和阳立高(2020),生产性服务业包括 7个细分行业:
| | |
|---|
| | |
| | |
| | 2003-2016含地质勘探,2017-2019不含 |
| | |
| | |
| | |
| | |
注意:科学研究和技术服务业在2003-2016年统计口径含"地质勘探业",2017-2019年不含。处理时用 combine_first() 合并两套口径(等价于 R 的 coalesce())。
2.3 就业数据说明
- 数据来自《中国城市统计年鉴》城镇单位从业人员(全市口径)
三、使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错:
ERROR: The requested version of Python cannot be used, as another version has already been initialized.因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
3.1 安装 reticulate(仅首次)
options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))3.2 虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
.venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name) .venv_python <- virtualenv_python(.venv_name)# 通过环境变量抢先锁定 Python(优先级最高,早于任何 {python} chunk)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)这样做的关键在于:knitr 在处理第一个 {python} chunk 时,reticulate 已经通过 RETICULATE_PYTHON 环境变量知道要使用 .venv,不会再去碰 Anaconda。
3.3 在虚拟环境中安装 Python 包(仅首次)
py_pkgs <- c("pandas", "numpy")installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")3.4 验证激活状态
3.5 虚拟环境管理常用命令
# virtualenv_remove(".venv")# virtualenv_install(".venv", packages = "pandas", ignore_installed = TRUE)
四、Python 代码实现
4.1 环境准备与数据读取
# ============================================================# 测算各城市生产性服务业集聚水平(专业化集聚 SP + 多样化集聚 DV)# 数据来源:中国城市统计年鉴地级市面板数据(1998~2024年)# 测算方法:参考 金培振等(2026)《生产性服务业集聚何以赋能技术扩散》# 《世界经济》2026年第3期,公式(4)(5)# ============================================================# df_raw = pd.read_stata("1998~2024年中国城市统计年鉴地级市面板数据.dta")df_raw = pd.read_stata("城市统计年鉴样本数据.dta")print(f"原始数据: {len(df_raw)} 行,{len(df_raw.columns)} 个变量")R vs Python 关键函数对照:
| | |
|---|
read_dta() | pd.read_stata() | |
library(tidyverse) | import pandas as pd | |
4.2 变量选取与数据清洗
# ============================================================# 生产性服务业包括 7 个细分行业(参考 Ke et al.2014;韩峰和阳立高2020)# ============================================================print(f"样本量(城市×年份): {len(df)}")print(f"年份范围: {df['year'].min()} ~ {df['year'].max()}")关键函数对照:
| | |
|---|
rename(new = old) | .rename(columns={'old': 'new'}) | |
coalesce(a, b) | a.combine_first(b) | |
filter(cond) | df[cond] | |
pmax(x, 0) | x.clip(lower=0) | |
rowSums(select(...)) | df[cols].sum(axis=1) | |
4.3 异常值处理
# ============================================================# (1) 嘉峪关市2013年:不在本样本年份范围内,自动跳过# (2) 鹤壁市2013年:不在本样本年份范围内,自动跳过# (3) 攀枝花市2018年:批发零售 = 129,241 人(占总就业 45%)# 处理:不单独剔除,在最终步骤对 DV 做 1% Winsorize 统一处理# ============================================================# --- (1) 修复嘉峪关市 2013 年 emp_total ---jyg_2013 = df[(df['city'] == '嘉峪关市') & (df['year'] == 2013)] jyg_neighbors = df[(df['city'] == '嘉峪关市') & (df['year'].isin([2012, 2014]))]iflen(jyg_neighbors) > 0: jyg_fix = jyg_neighbors['emp_total'].mean()print(f"嘉峪关市 2013 年 emp_total 修复:{jyg_fix:.0f}") df.loc[(df['city'] == '嘉峪关市') & (df['year'] == 2013), 'emp_total'] = jyg_fixprint("(嘉峪关市2013年不在2017-2019样本,跳过修复)")# --- (2) 剔除鹤壁市 2013 年 ---df = df[~((df['city'] == '鹤壁市') & (df['year'] == 2013))].reset_index(drop=True)print(f"鹤壁市2013年:剔除前 {n_before} 条 → 剔除后 {len(df)} 条")print("(鹤壁市2013年不在2017-2019样本,跳过剔除)")print(f"\n异常值处理后样本量: {len(df)}")4.4 计算全国层面基准(按年份)
# ============================================================# E_nat = 全国城镇单位从业人员总数(各城市加总)# nat_emp_sX = 全国生产性服务业行业X就业总数(各城市加总)# nat_pbs_share = 全国生产性服务业7行业就业合计 / 全国总就业# ============================================================# 按年份汇总全国数据(等价于 R 的 group_by(year) %>% summarise(...))agg_dict = {'emp_total': 'sum'}agg_dict.update({col: 'sum'for col in sector_cols})nat_by_year = df.groupby('year').agg(agg_dict).reset_index()nat_by_year = nat_by_year.rename(columns={'emp_total': 'E_nat'})nat_by_year = nat_by_year.rename( columns={f'emp_s{i}': f'nat_emp_s{i}'for i inrange(1, 8)}nat_sector_cols = [f'nat_emp_s{i}'for i inrange(1, 8)]nat_by_year['nat_pbs_total'] = nat_by_year[nat_sector_cols].sum(axis=1)nat_by_year['nat_pbs_share'] = nat_by_year['nat_pbs_total'] / nat_by_year['E_nat']nat_by_year = nat_by_year.drop(columns=['nat_pbs_total'])print(f"全国层面基准计算完成,年份数: {len(nat_by_year)}")print(nat_by_year[['year', 'E_nat', 'nat_pbs_share']].to_string(index=False))关键函数对照:
| | |
|---|
group_by(year) %>% summarise(sum(...)) | .groupby('year').agg({'col': 'sum'}) | |
across(starts_with("nat_emp_s"), sum) | dict comprehension + agg | |
rowSums(select(starts_with(...))) | df[cols].sum(axis=1) | |
4.5 测算专业化集聚指数 SP(公式4)
# ============================================================# SP_i = ∑_s(E_is/E_i) / ∑_s(E_s/E)# = [城市生产性服务业7行业就业 / 城市总就业] /# [全国生产性服务业7行业就业 / 全国总就业]# ============================================================print(f"SP 计算完成,样本量: {len(df_sp)}")print(df_sp['SP'].describe().round(4))4.6 测算多样化集聚指数 DV(公式5)
DV 的计算需要对每个城市×年份进行双重循环。Python 使用自定义函数 calc_dv() 逐行调用(等价于 R 的 rowwise() %>% mutate(DV = calc_dv(...)))。
# ============================================================# DV_i = ∑_s (E_{i,s}/E_i) × [ ∑_{s'≠s} [E_{s'}/(E-E_s)]^2# / ∑_{s'≠s} [E_{i,s'}/(E_i-E_{i,s})]^2 ]# 关键:份额 = 其余行业就业 / 剩余就业(非总就业)# ============================================================print(f"DV 计算完成,样本量: {len(df_dv)}")print(df_dv['DV'].describe().round(4))calc_dv() 函数与 R 版本的对应关系:
| | |
|---|
seq_len(n_sectors)[-s] | [i for i in range(n) if i != s] | |
city_emp[others] | city_emp[others] | |
sum(x^2) | np.sum(x ** 2) | |
is.na(x) || x <= 0 | np.isnan(x) or x <= 0 | |
rowwise() %>% mutate(DV = calc_dv(...)) | for _, row in df.iterrows() | |
4.7 缩尾处理与结果保存
# ============================================================# 六、合并 SP 和 DV,并进行缩尾处理(Winsorize)# ============================================================print(f" 处理后范围: {df_result['生产性服务业多样化集聚DV'].min():.4f} ~ "f"{df_result['生产性服务业多样化集聚DV'].max():.4f}")# ============================================================# ============================================================print("=== 最终结果数据概览(2017-2019年)===")print(f"总行数: {len(df_result)}")print(f"年份范围: {df_result['year'].min()} ~ {df_result['year'].max()}")print(df_result.groupby('year').size().rename('城市数').reset_index().to_string(index=False))print("\nSP(专业化集聚)描述性统计:")print(df_result['SP'].describe().round(4))print("\nDV(多样化集聚,经1% Winsorize)描述性统计:")print(df_result['生产性服务业多样化集聚DV'].describe().round(4))print(df_result[['year', 'prov', 'city', 'SP', '生产性服务业多样化集聚DV']].head(10).to_string(index=False))# ============================================================# ============================================================year_min = df_result['year'].min()year_max = df_result['year'].max()output_filename = f"{year_min}~{year_max}年各城市生产性服务业集聚水平.csv"df_out = df_result.rename(columns={df_out.to_csv(output_filename, index=False, encoding='utf-8-sig')print(f"已保存: {output_filename}")
五、结果验证:与论文对比
5.1 SP 指标验证
论文报告 SP 均值约为 0.83。
sp_mean = df_result['SP'].mean()print(f"SP 均值: {sp_mean:.4f}")print(f"论文报告 SP 均值: 0.83")print(f"差距: {sp_mean - 0.83:.4f}")结论:SP 均值与论文报告的 0.83 高度吻合 ✅(本样本仅为 2017-2019 年子集,故略有差异)
5.2 DV 指标验证
论文报告 DV 均值约为 0.28。
dv_mean = df_result['生产性服务业多样化集聚DV'].mean()print(f"DV 均值(1% Winsorize后): {dv_mean:.4f}")print(f"论文报告 DV 均值: 0.28")print(f"差距: {dv_mean - 0.28:.4f}")如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/3beb4a55ad9f48d7ae5da9cc7eb79d68








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
