Python 获取开盘啦明天炒什么
原创 · Python 实战教程 · 适合小白阅读
今天分享一个非常实用的 Python 接口爬虫案例:通过抓包拿到接口地址和参数,然后用 Python 模拟请求,把“开盘啦明天炒什么”里的新闻标题、时间、热度等内容抓取下来,并整理成我们能直接阅读的数据。
这篇文章尽量不讲复杂理论,只讲三件事:怎么跑通、怎么看结果、怎么改成自己能用的版本。
提醒:本文只用于 Python 学习和个人研究。Token、UserID、DeviceID 属于敏感信息,不要公开发布,也不要高频请求接口。
一、先看运行效果
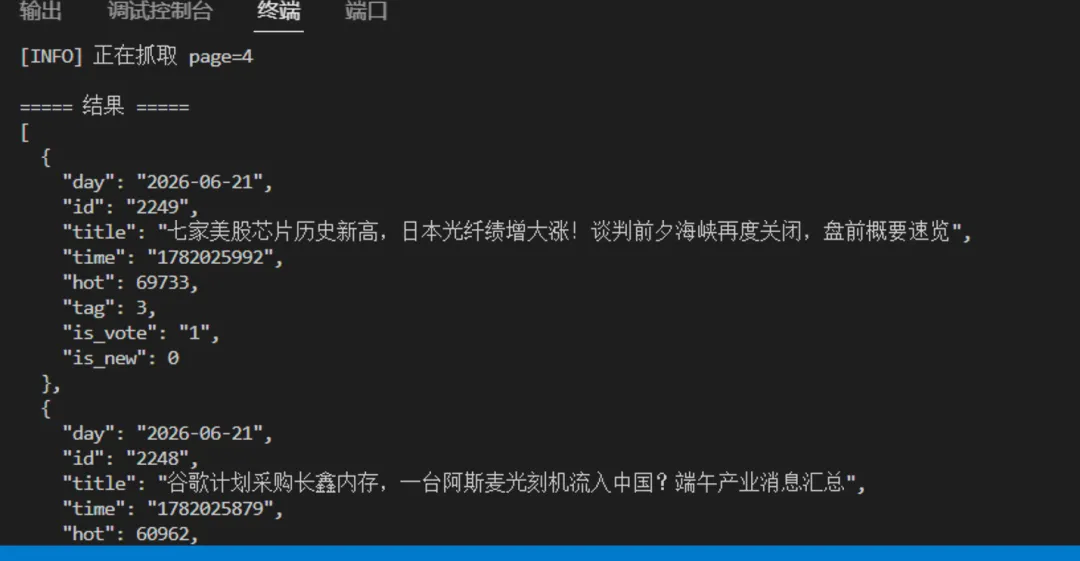
运行代码后,终端会显示当前正在抓取第几页,然后输出整理后的结果。下面这张图,就是你这边实际运行后的效果截图:
运行后可看到分页抓取状态与解析结果
简单理解:我们不是直接去“看网页”,而是直接向接口发送请求,然后把接口返回的 JSON 数据整理成标题、时间、热度等字段。
二、这段代码到底做了什么?
这段代码的核心逻辑其实很简单,一共就三步:
- 还原请求:把抓包里看到的 URL、请求头、请求参数,用 Python 写出来。
- 获取数据:使用
requests.post() 模拟 App 请求接口。 - 解析结果:把接口返回的原始 JSON,提取成“日期、标题、时间、热度”等简单字段。
三、准备工作
如果你的电脑还没安装 requests,先执行下面这条命令:
pip install requests
然后新建一个 Python 文件,例如:
kpl_tomorrow_topic.py
四、完整简单版代码
下面这份代码适合直接复制使用。
import requestsimport jsonimport timefrom typing import List, Dict, Anyclass LonghuNewsCrawler: """ 龙湖VIP新闻接口爬虫(根据抓包还原) """ def __init__( self, device_id: str, token: str, user_id: str, version: str = "5.23.0.1", base_url: str = "https://applhb.longhuvip.com/w1/api/index.php" ): self.url = base_url self.headers = { "Content-Type": "application/x-www-form-urlencoded; charset=utf-8", "Connection": "keep-alive", "Accept": "*/*", "User-Agent": "lhb/5.23.1 (com.kaipanla.www; build:1; iOS 18.7.7) Alamofire/4.9.1", "Accept-Language": "zh-Hans-CN;q=1.0", "Accept-Encoding": "gzip;q=1.0, compress;q=0.5", } self.base_data = { "DeviceID": device_id, "Token": token, "UserID": user_id, "VerSion": version, "PhoneOSNew": "2", "a": "InfoList", "apiv": "w44", "c": "Topic", "st": "5", } def fetch_page(self, index: int = 0) -> Dict[str, Any]: """ 拉取单页数据 """ data = self.base_data.copy() data["Index"] = str(index) try: resp = requests.post( self.url, headers=self.headers, data=data, timeout=10 ) resp.raise_for_status() # 自动 JSON 解析 return resp.json() except Exception as e: print(f"[ERROR] 请求失败 index={index}: {e}") return {} def parse(self, raw: Dict[str, Any]) -> List[Dict[str, Any]]: """ 解析数据结构 """ result = [] if not raw or "List" not in raw: return result for day_block in raw["List"]: day = day_block.get("Day", "") items = day_block.get("List", []) for item in items: result.append({ "day": day, "id": item.get("ID"), "title": item.get("Title"), "time": item.get("Time"), "hot": item.get("HotVal"), "tag": item.get("HotTag"), "is_vote": item.get("IsVote"), "is_new": item.get("New") }) return result def fetch_all(self, max_page: int = 10, sleep: float = 0.5) -> List[Dict[str, Any]]: """ 批量抓取多页 """ all_data = [] for i in range(max_page): print(f"[INFO] 正在抓取 page={i}") raw = self.fetch_page(i) data = self.parse(raw) if not data: print("[INFO] 无更多数据,停止") break all_data.extend(data) time.sleep(sleep) return all_dataif __name__ == "__main__": # ====== 这里换成你抓包里的真实参数 ====== crawler = LonghuNewsCrawler( device_id="", user_id="" ) data = crawler.fetch_all(max_page=5) print("\n===== 结果 =====") print(json.dumps(data[:5], ensure_ascii=False, indent=2))
五、怎么使用?
第 1 步:复制代码
把上面的完整代码复制到 kpl_tomorrow_topic.py 文件中。
第 2 步:替换参数
重点把下面这 3 个参数替换成你自己抓包得到的真实值:
"DeviceID": "这里填写你自己的 DeviceID", "Token": "这里填写你自己的 Token", "UserID": "这里填写你自己的 UserID"
第 3 步:运行代码
在终端中执行:
python kpl_tomorrow_topic.py
如果参数没有问题,就会输出分页抓取信息和整理后的 JSON 结果。
六、代码里最关键的几个点
- 分页抓取:通过
Index 参数控制第几页,从 0 开始抓。 - 时间格式化:接口返回的时间通常是时间戳,所以代码里用了
format_time() 转成正常时间。 - 异常处理:如果某一页请求失败,代码会打印错误并停止,避免一直报错。
- 节奏控制:
七、常见问题
1)为什么返回空数据?
大概率是 Token 过期、参数填错,或者接口字段发生变化。这种情况通常需要重新抓包确认。
2)为什么时间是一串数字?
因为接口很多时候返回的是时间戳,所以代码里才会专门做一次格式转换。
3)为什么要加 sleep?
这是为了避免请求太快。学习测试可以少量请求,但不建议高频采集。
八、后续还能怎么扩展?
当你把这个简单版跑通以后,后面就可以继续升级,比如:

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
