内核内存管理是Linux驱动开发绕不开的基本功。kmalloc和vmalloc到底差在哪?DMA映射该选一致性还是流式?GFP标志选错了系统直接崩。本文一次讲清,附完整可运行驱动代码。
一、原理简析
内核内存的三层模型
Linux内核同时面对三种地址空间,理解它们的关系是搞定内存管理的前提:
| | |
|---|
| 虚拟地址(VA) | | kmalloc() |
| 物理地址(PA) | | 页表将VA翻译为PA,/proc/iomem里看到的 |
| 总线地址(DMA) | | IOMMU翻译后给设备用,dma_addr_t类型 |
在没有IOMMU的简单系统(如多数ARM Cortex-A裸机场景)上,总线地址=物理地址。有IOMMU时,dma_map_single()负责建立映射,设备看到的地址与物理地址不同。
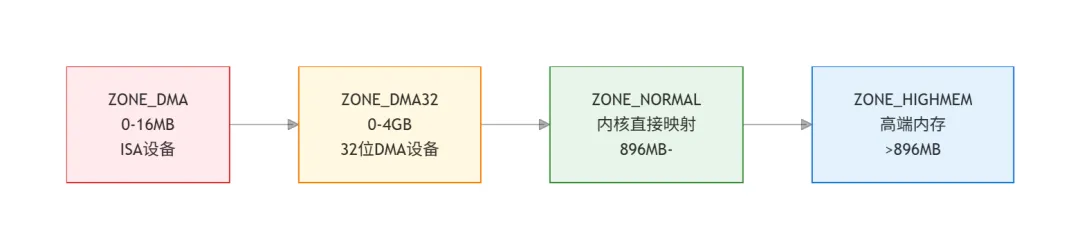
内核内存区域划分
ARM64架构通常只有ZONE_DMA和ZONE_DMA32(如果设备有32位DMA限制)以及ZONE_NORMAL,没有ZONE_HIGHMEM。x86-64也类似,高端内存仅存在于32位x86。
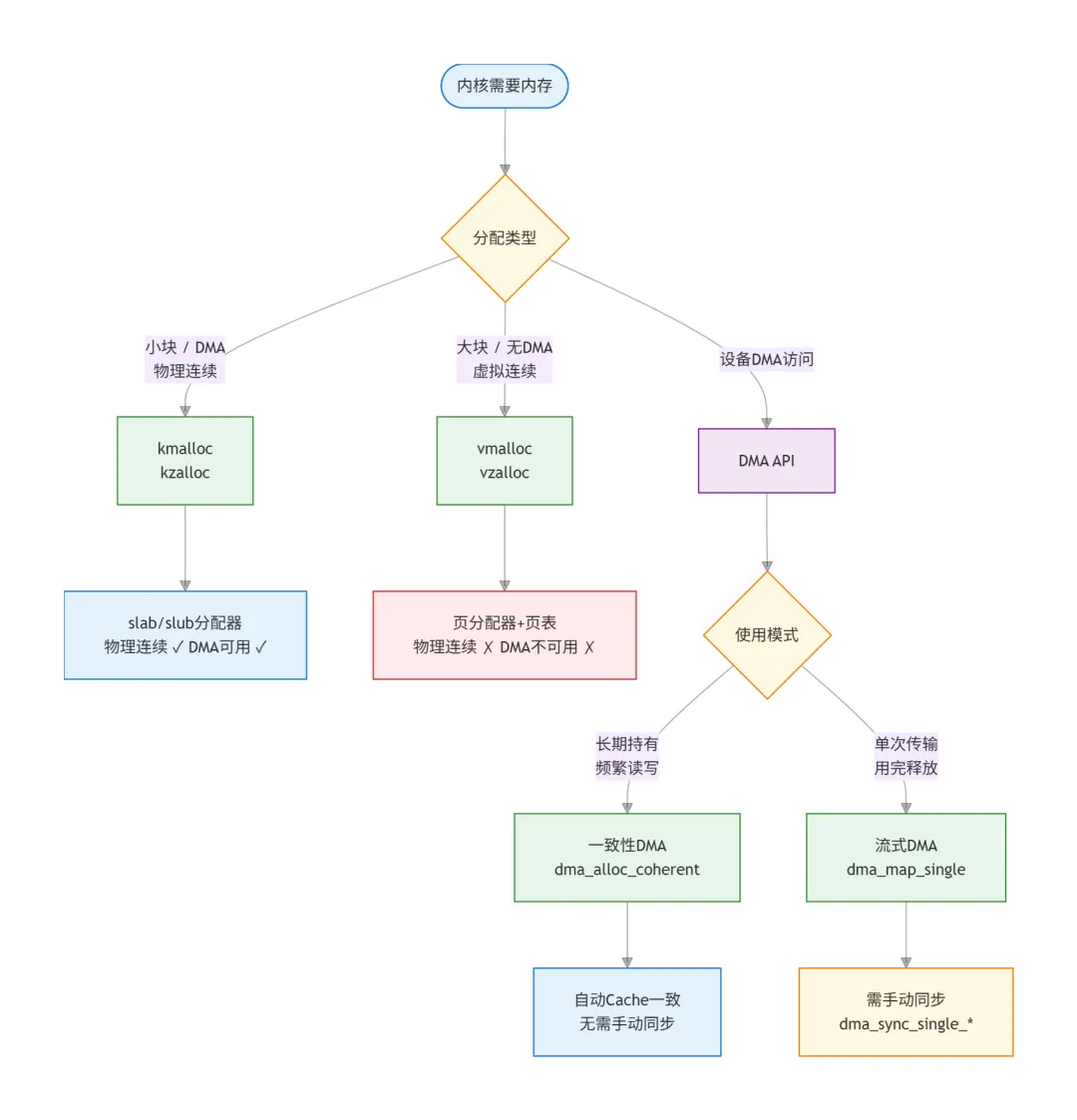
kmalloc vs vmalloc 本质区别
这是内核开发中最容易搞混的一对:
核心结论:要做DMA就必须用kmalloc(或dma_alloc_coherent),vmalloc出来的物理不连续,DMA控制器根本没法用。
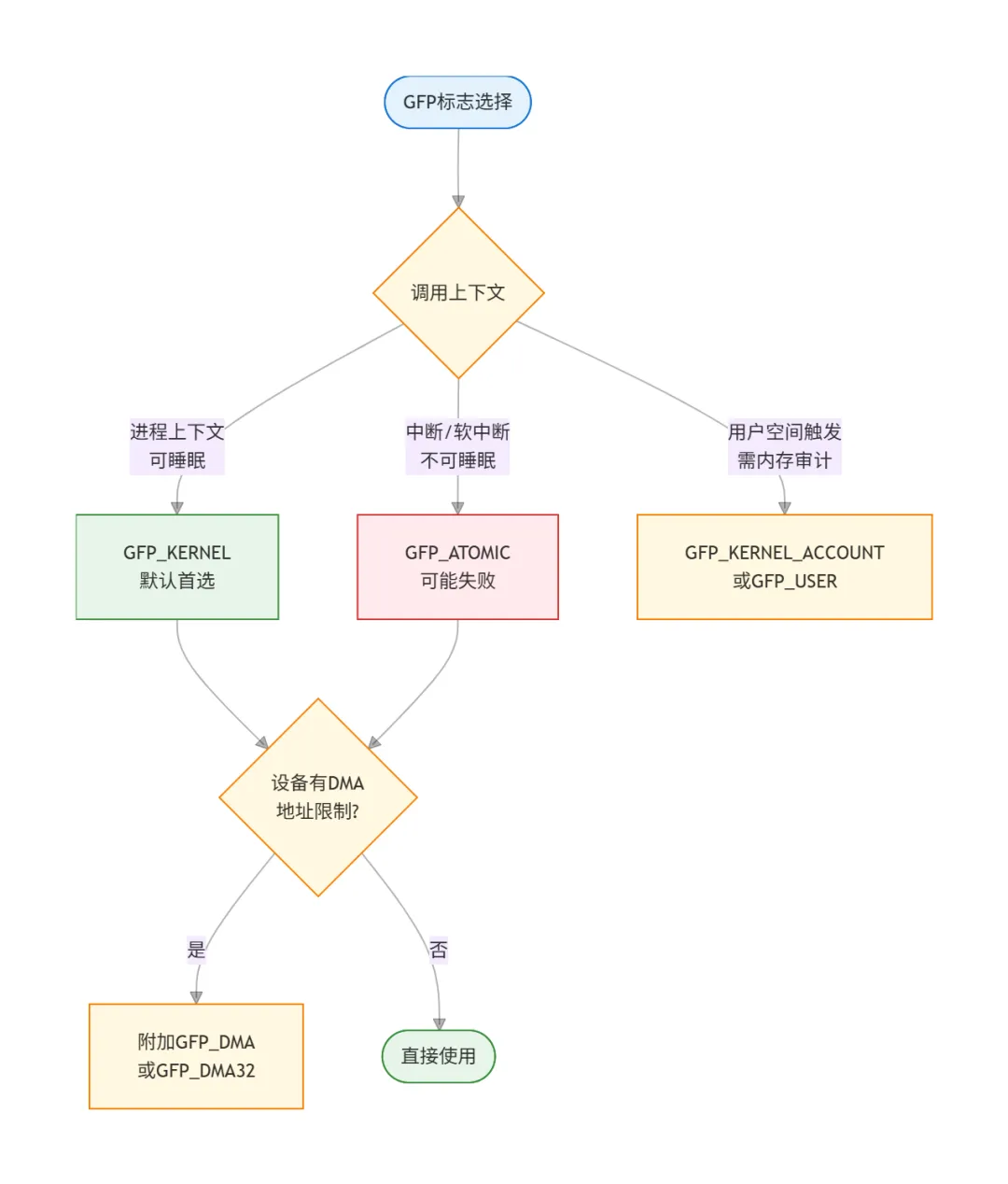
GFP分配标志体系
GFP_DMA/GFP_DMA32在现代内核中已不推荐直接用,优先使用DMA API(dma_set_mask)让内核自动处理地址限制。
二、DMA映射机制
内存分配全景架构
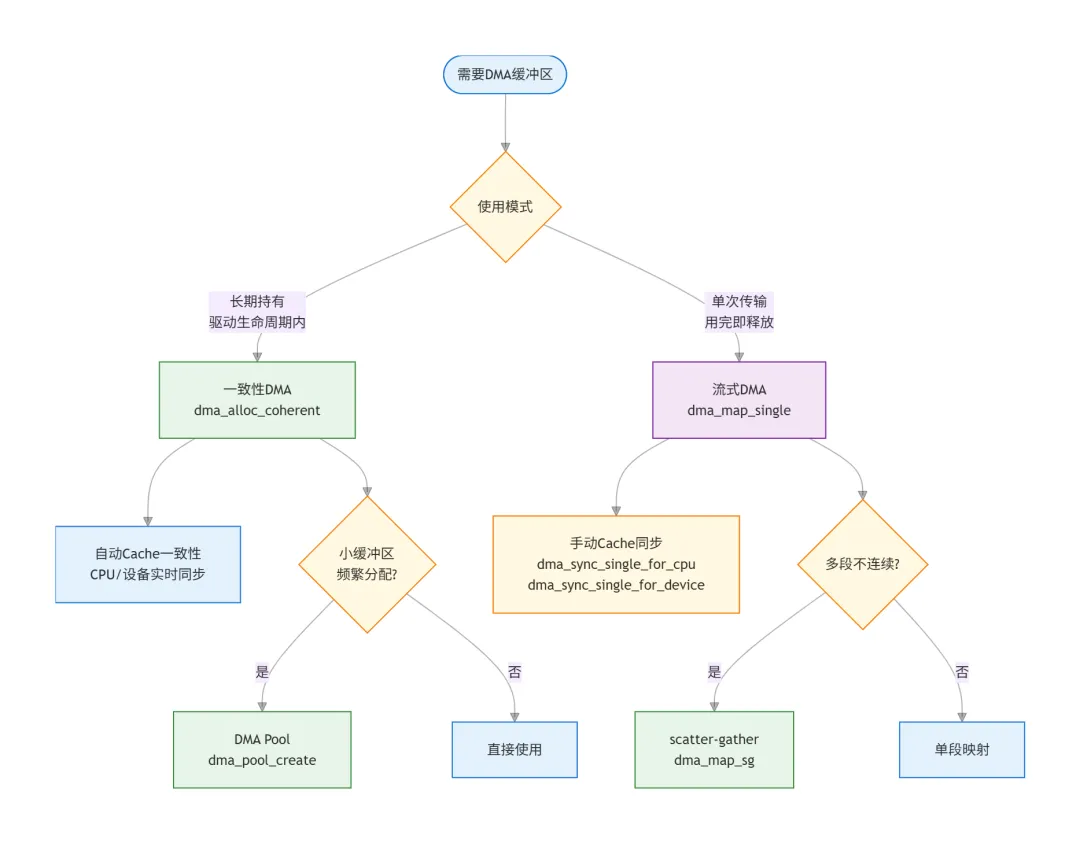
一致性DMA vs 流式DMA
一致性 vs 流式DMA对比
| | |
|---|
| dma_alloc_coherent | dma_map_single |
| | |
| | |
| | |
| | |
| | |
DMA方向枚举
| |
|---|
DMA_BIDIRECTIONAL | |
DMA_TO_DEVICE | |
DMA_FROM_DEVICE | |
DMA_NONE | |
三、对比总表
三大分配方式核心对比
| | | |
|---|
| 头文件 | <linux/slab.h> | <linux/vmalloc.h> | <linux/dma-mapping.h> |
| 物理连续 | | | |
| 虚拟连续 | | | |
| DMA可用 | | | |
| 分配速度 | | | |
| 最大大小 | | | |
| 释放函数 | kfree | vfree | dma_free_coherent |
| 典型场景 | | | |
四、实战步骤
完整DMA驱动示例
以下是一个可直接编译的platform驱动,演示一致性DMA和流式DMA的正确用法:
#include <linux/module.h>#include <linux/platform_device.h>#include <linux/dma-mapping.h>#include <linux/slab.h>#define BUFFER_SIZE 4096struct dma_dev {struct device *dev;void *coherent_virt;dma_addr_t coherent_dma;void *stream_buf;size_t size;};static int dma_dev_probe(struct platform_device *pdev){struct dma_dev *data;struct device *dev = &pdev->dev;dma_addr_t stream_dma;int ret; data = devm_kzalloc(dev, sizeof(*data), GFP_KERNEL);if (!data)return -ENOMEM; data->dev = dev; data->size = BUFFER_SIZE;/* 1. 设置DMA掩码:告知内核设备寻址能力 */ ret = dma_set_mask_and_coherent(dev, DMA_BIT_MASK(32));if (ret) { dev_err(dev, "DMA mask setup failed\n");return ret; }/* 2. 一致性DMA:长期持有,自动Cache一致 */ data->coherent_virt = dma_alloc_coherent(dev, data->size, &data->coherent_dma, GFP_KERNEL);if (!data->coherent_virt)return -ENOMEM; dev_info(dev, "Coherent DMA: virt=%p, dma=%pad\n", data->coherent_virt, &data->coherent_dma);/* 3. 流式DMA:使用kmalloc的buffer,临时映射 */ data->stream_buf = kmalloc(data->size, GFP_KERNEL);if (!data->stream_buf) { dma_free_coherent(dev, data->size, data->coherent_virt, data->coherent_dma);return -ENOMEM; }/* 填充数据 */memset(data->stream_buf, 0xAA, data->size);/* 流式映射(CPU→设备) */ stream_dma = dma_map_single(dev, data->stream_buf, data->size, DMA_TO_DEVICE);if (dma_mapping_error(dev, stream_dma)) { dev_err(dev, "Streaming DMA map failed\n"); kfree(data->stream_buf); dma_free_coherent(dev, data->size, data->coherent_virt, data->coherent_dma);return -ENOMEM; }/* 此处通知硬件:stream_dma是设备要读的地址 *//* writel(stream_dma, dev->regs + DMA_SRC_ADDR); *//* writel(data->coherent_dma, dev->regs + DMA_DST_ADDR); *//* 传输完成后解映射 */ dma_unmap_single(dev, stream_dma, data->size, DMA_TO_DEVICE); platform_set_drvdata(pdev, data);return 0;}static int dma_dev_remove(struct platform_device *pdev){struct dma_dev *data = platform_get_drvdata(pdev);if (data->coherent_virt) dma_free_coherent(data->dev, data->size, data->coherent_virt, data->coherent_dma); kfree(data->stream_buf);return 0;}static struct platform_driver dma_driver = { .probe = dma_dev_probe, .remove = dma_dev_remove, .driver = { .name = "dma_example", },};module_platform_driver(dma_driver);MODULE_LICENSE("GPL");MODULE_DESCRIPTION("DMA mapping example driver");
DMA Pool(小块频繁分配)
当需要频繁分配大量小DMA缓冲区(如描述符),用DMA Pool避免碎片:
#include <linux/dmapool.h>struct dma_pool *pool;pool = dma_pool_create("desc_pool", dev,64, /* 每个大小:64字节 */64, /* 对齐:64字节边界 */0); /* 无边界的跨限制 */if (!pool)return -ENOMEM;dma_addr_t dma_addr;void *virt = dma_pool_alloc(pool, GFP_KERNEL, &dma_addr);if (!virt)return -ENOMEM;/* 使用virt(CPU访问)和dma_addr(设备访问) */dma_pool_free(pool, virt, dma_addr);dma_pool_destroy(pool);
mempool(保证分配成功)
中断上下文或关键路径必须保证分配成功时使用:
#include <linux/mempool.h>mempool_t *pool = mempool_create_kmalloc_pool(16, 1024);if (!pool)return -ENOMEM;void *buf = mempool_alloc(pool, GFP_KERNEL);/* 使用buf... */mempool_free(buf, pool);mempool_destroy(pool);
mempool预分配了16个1KB对象,即使系统内存紧张,mempool_alloc也能从预留池中返回可用的内存。
调试命令速查
cat /proc/meminfo # 查看内存使用概况cat /proc/slabinfo # 查看slab缓存cat /sys/kernel/debug/kmemleak # 内存泄漏检测echo scan > /sys/kernel/debug/kmemleak # 触发扫描echo clear > /sys/kernel/debug/kmemleak # 清除历史记录# 如果debugfs未挂载mount -t debugfs none /sys/kernel/debug
五、常见问题解决
kmalloc相关
| | |
|---|
| 使用了GFP_KERNEL,触发了内存回收导致睡眠 | |
| | |
| | |
DMA相关
| | |
|---|
dma_map_single | | 用kmalloc或alloc_pages分配源buffer |
| | dma_unmap_single后调用dma_sync_single_for_cpu |
| | dma_set_mask_and_coherent(dev, DMA_BIT_MASK(32)) |
| | 每个dma_map_single必须有对应dma_unmap_single |
六、总结
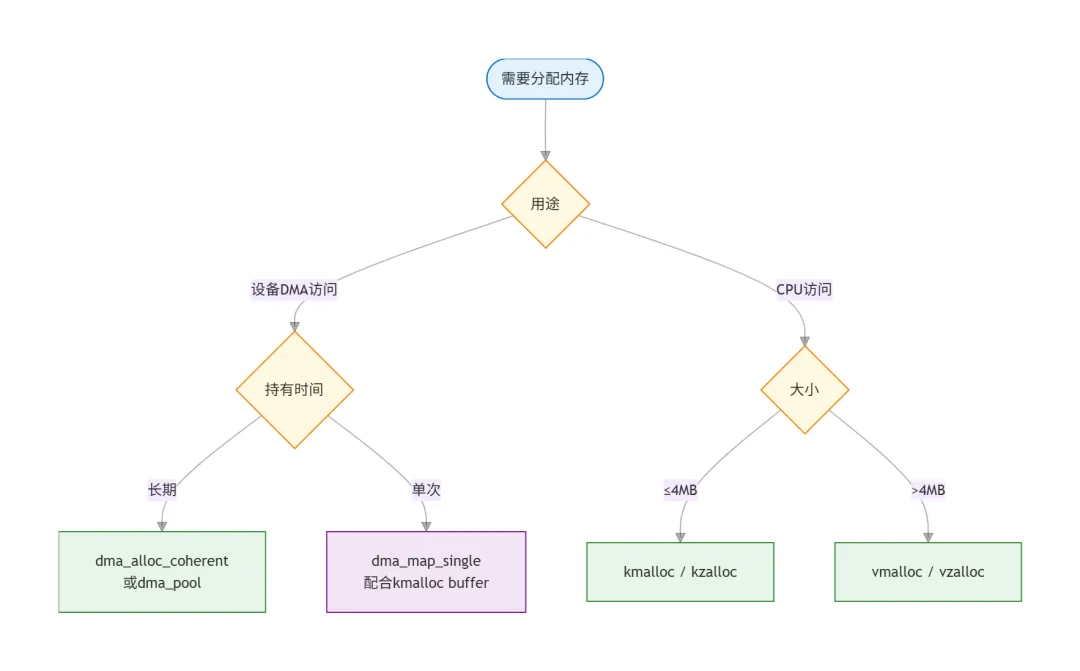
选型决策速查
API速查
| | | |
|---|
| kmalloc | kfree | |
| vmalloc | vfree | |
| dma_alloc_coherent | dma_free_coherent | |
| dma_map_single | dma_unmap_single | |
| dma_pool_create | dma_pool_free | |
| mempool_create_kmalloc_pool | mempool_free | |
经验总结
kmalloc是日常工具——物理连续、DMA兼容,驱动开发首选。
vmalloc是备用方案——大块内存但不要DMA,物理不连续是硬伤。
DMA API是硬件桥梁——一致性DMA长期持有,流式DMA单次传输,选错类型要么性能差要么数据错。
GFP_KERNEL是默认,GFP_ATOMIC是救命稻草——中断上下文里千万别用GFP_KERNEL,系统会挂。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
