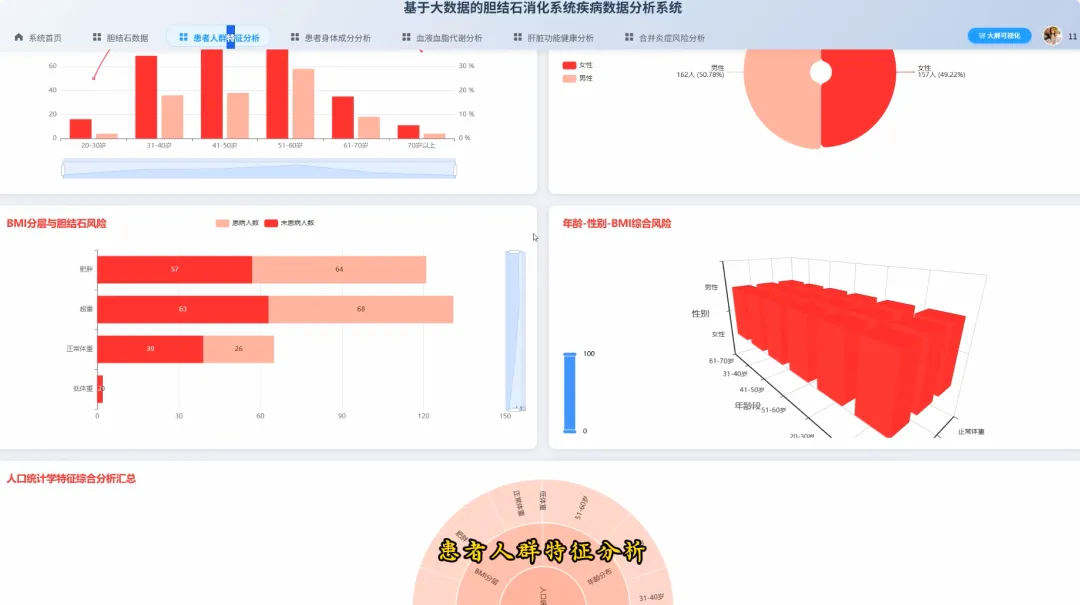
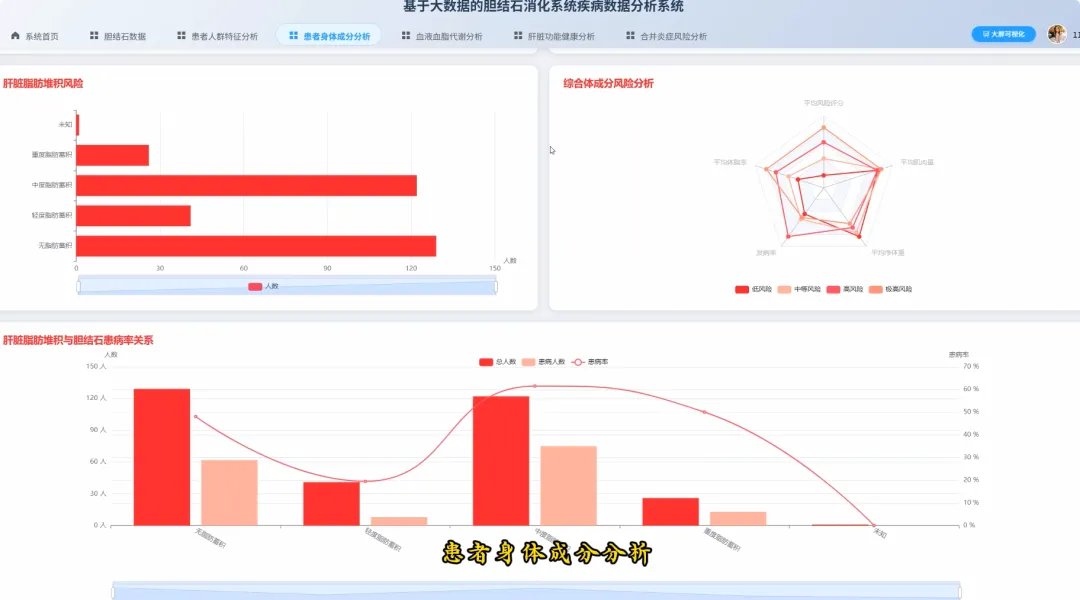
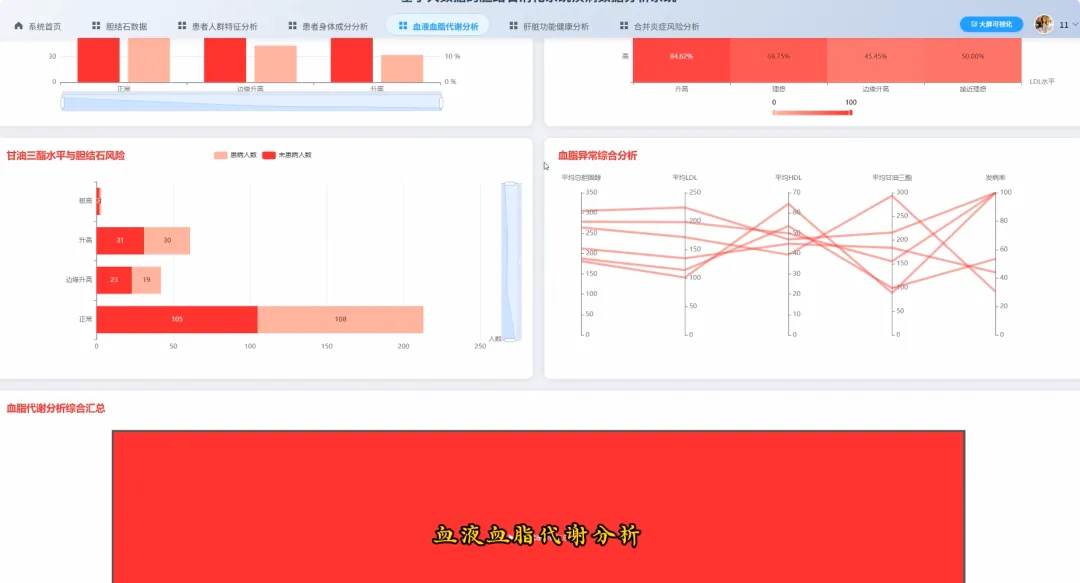
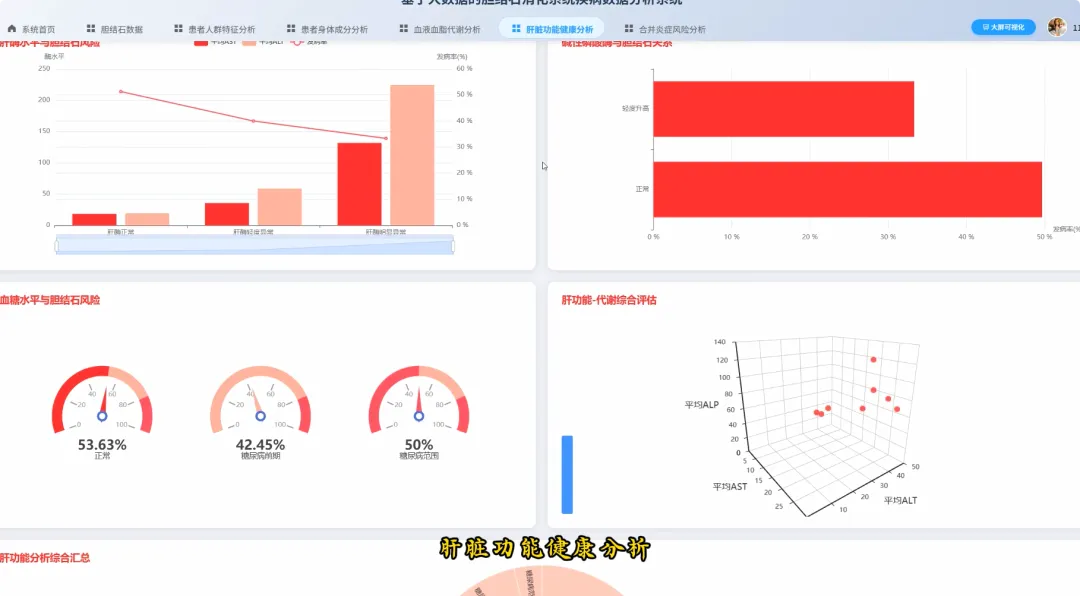
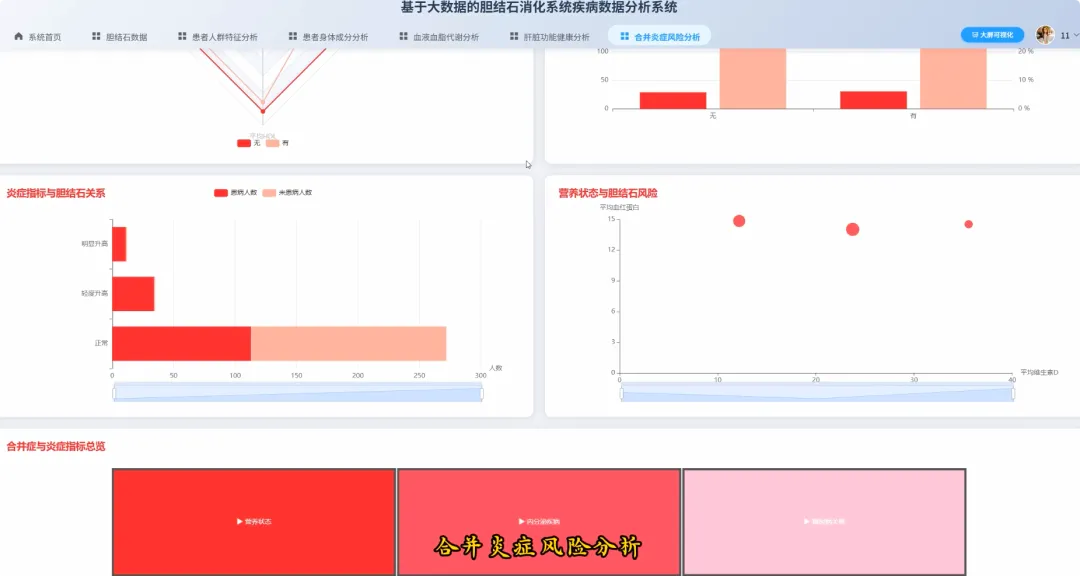
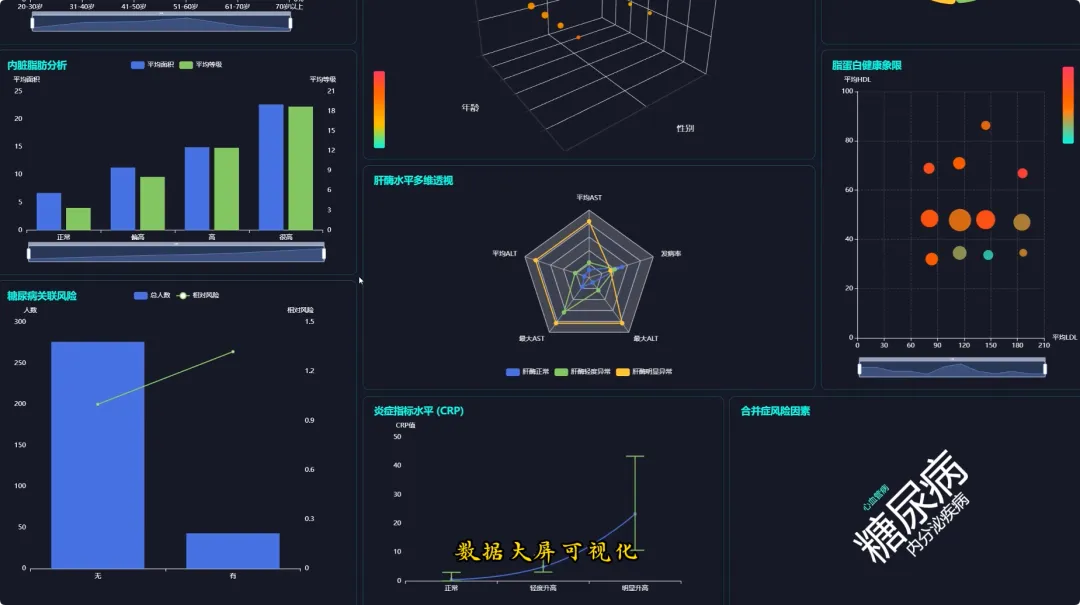
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, when, count, avg, corrdef analyze_demographics_risk(df): age_groups = when((col("Age") >= 20) & (col("Age") <= 30), "20-30") \ .when((col("Age") >= 31) & (col("Age") <= 40), "31-40") \ .when((col("Age") >= 41) & (col("Age") <= 50), "41-50") \ .when((col("Age") >= 51) & (col("Age") <= 60), "51-60") \ .when((col("Age") >= 61) & (col("Age") <= 70), "61-70") \ .otherwise("71+") df_with_group = df.withColumn("AgeGroup", age_groups) risk_analysis = df_with_group.groupBy("AgeGroup", "Gender") \ .agg((count(when(col("Gallstone Status") == 1, True)) / count("*")).alias("Incidence_Rate"), avg("Body Mass Index (BMI)").alias("Avg_BMI")) \ .orderBy("AgeGroup", "Gender") return risk_analysisdef analyze_body_composition_risk(df): df_bmi_category = df.withColumn("BMI_Category", when(col("Body Mass Index (BMI)") < 18.5, "Underweight") \ .when((col("Body Mass Index (BMI)") >= 18.5) & (col("Body Mass Index (BMI)") < 25), "Normal") \ .when((col("Body Mass Index (BMI)") >= 25) & (col("Body Mass Index (BMI)") < 30), "Overweight") \ .otherwise("Obese")) composition_risk = df_bmi_category.groupBy("BMI_Category") \ .agg(avg("Total Body Fat Ratio (TBFR)").alias("Avg_Body_Fat_Ratio"), avg("Visceral Fat Area (VFA)").alias("Avg_Visceral_Fat_Area"), (count(when(col("Gallstone Status") == 1, True)) / count("*")).alias("Incidence_Rate")) \ .orderBy(col("Incidence_Rate").desc()) return composition_riskdef analyze_lipid_metabolism_correlation(df): lipid_correlation = df.select(corr("Total Cholesterol (TC)", "Gallstone Status").alias("TC_Correlation"), corr("Low Density Lipoprotein (LDL)", "Gallstone Status").alias("LDL_Correlation"), corr("Triglyceride", "Gallstone Status").alias("TG_Correlation"), corr("High Density Lipoprotein (HDL)", "Gallstone Status").alias("HDL_Correlation")) hyperlipidemia_impact = df.groupBy("Hyperlipidemia") \ .agg((count(when(col("Gallstone Status") == 1, True)) / count("*")).alias("Incidence_Rate")) \ .filter(col("Hyperlipidemia") == 1) combined_result = lipid_correlation.crossJoin(hyperlipidemia_impact) return combined_result

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
