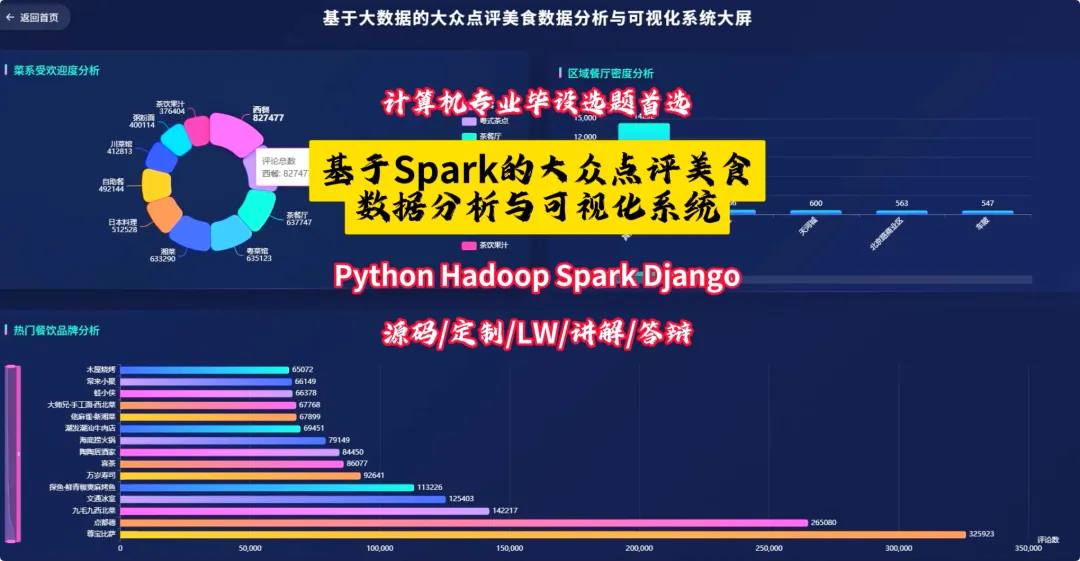
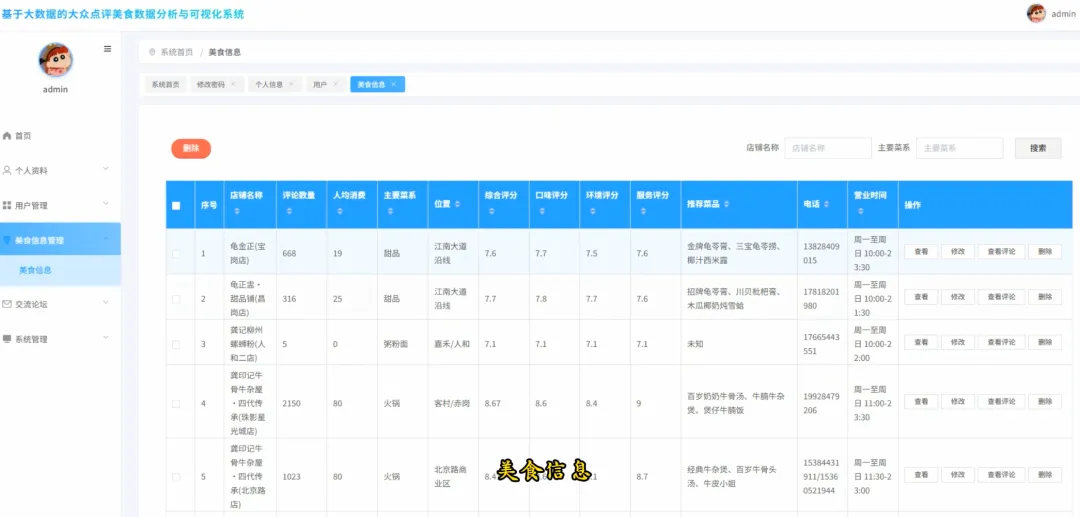
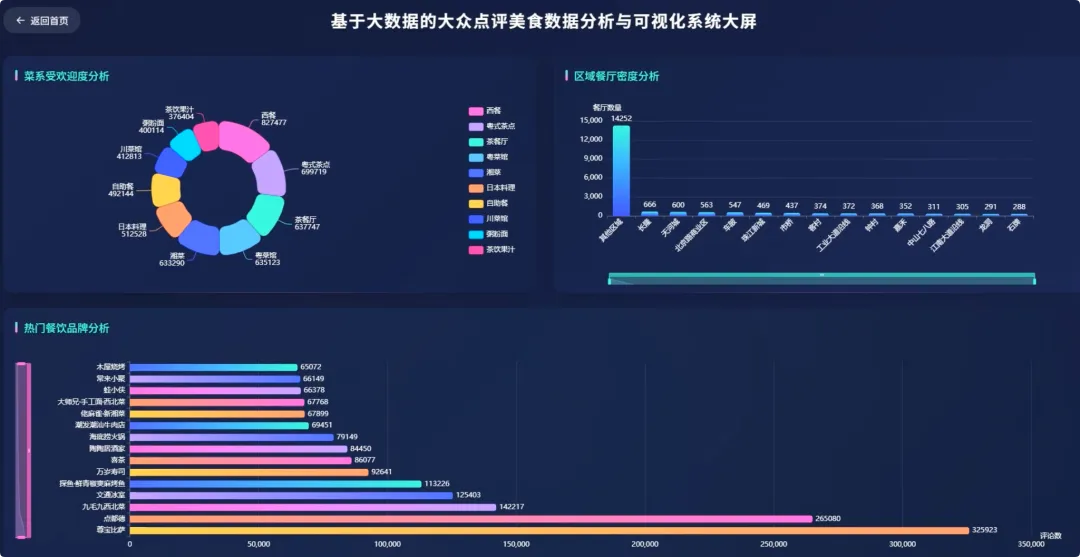
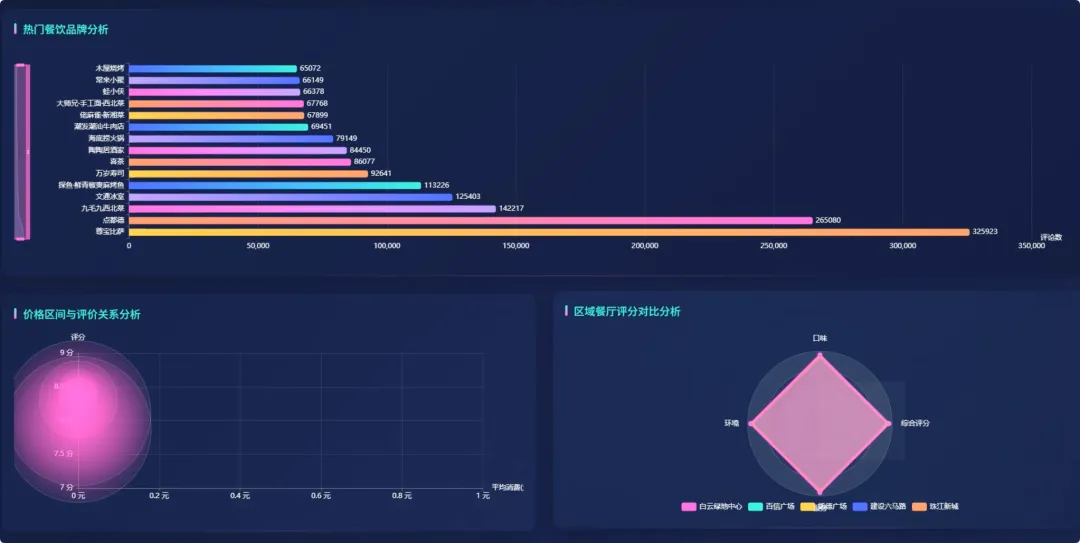
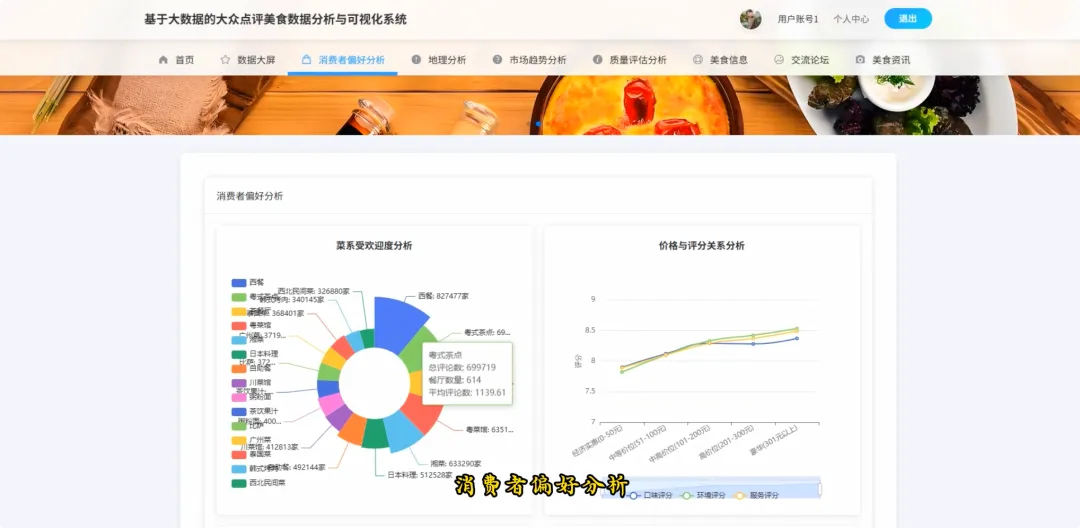
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, split, count, avg, sum as _sum, when, regexp_extractfrom pyspark.sql.types import FloatTypespark = SparkSession.builder.appName("DianpingAnalysis").getOrCreate()# 核心功能1: 区域餐厅密度分析def analyze_regional_density(df): # 使用正则表达式从地址中提取区级信息,如“朝阳区” df_region = df.withColumn("region", regexp_extract(col("address"), "(.*?区|.*?县)", 1)) # 按区域分组并统计餐厅数量 density_df = df_region.groupBy("region").agg(count("shop_id").alias("restaurant_count")) # 按餐厅数量降序排列,找出最密集的区域 result_df = density_df.orderBy(col("restaurant_count").desc()) return result_df# 核心功能2: 高性价比餐厅特征分析def analyze_cost_effectiveness(df): # 定义一个简单的性价比指标:(口味+环境+服务)评分 / 人均消费 # 需要处理人均消费为0或空值的情况,避免除零错误 df = df.filter((col("avg_price") > 0) & (col("detail_rating").isNotNull())) # 假设detail_rating是一个结构体类型,包含taste, environment, service # 这里简化处理,假设可以直接获取总分或平均分 df_with_ratio = df.withColumn("cost_effectiveness", (col("detail_rating.taste") + col("detail_rating.environment") + col("detail_rating.service")) / col("avg_price") ) # 筛选出性价比高的餐厅,例如指标大于某个阈值 high_value_df = df_with_ratio.filter(col("cost_effectiveness") > 0.5) # 选择关键信息并按性价比指标降序排列 result_df = high_value_df.select("shop_name", "main_cuisine", "avg_price", "cost_effectiveness").orderBy(col("cost_effectiveness").desc()) return result_df# 核心功能3: 菜系受欢迎度分析def analyze_cuisine_popularity(df): # 过滤掉菜系信息为空的记录 df_cuisine = df.filter(col("main_cuisine").isNotNull()) # 按主营菜系分组,计算总评论数和平均评论数 popularity_df = df_cuisine.groupBy("main_cuisine").agg( _sum("review_count").alias("total_reviews"), avg("review_count").alias("avg_reviews_per_shop") ) # 按总评论数降序排列,总评论数越高通常代表越受欢迎 result_df = popularity_df.orderBy(col("total_reviews").desc()) return result_df

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
