抽絲剝繭,用python來對網頁進行,外科手術般的解剖.
做為一個重症偏IT男,對記算機書籍是達到了風魔的地步。沒事的時候,就喜歡在網上做街溜子,找到一兩本能看得下的書。
瓦聯網如同一片沙灘,想從中獲取自己對上眼的東西,如同淘金一些的難。
這幾天接觸了python中的bf4,又覺得找一本書名和他的web地址不是太難。
下面我就從我,逛的比較多的一個網頁來寫一下。
基部分html源碼如下
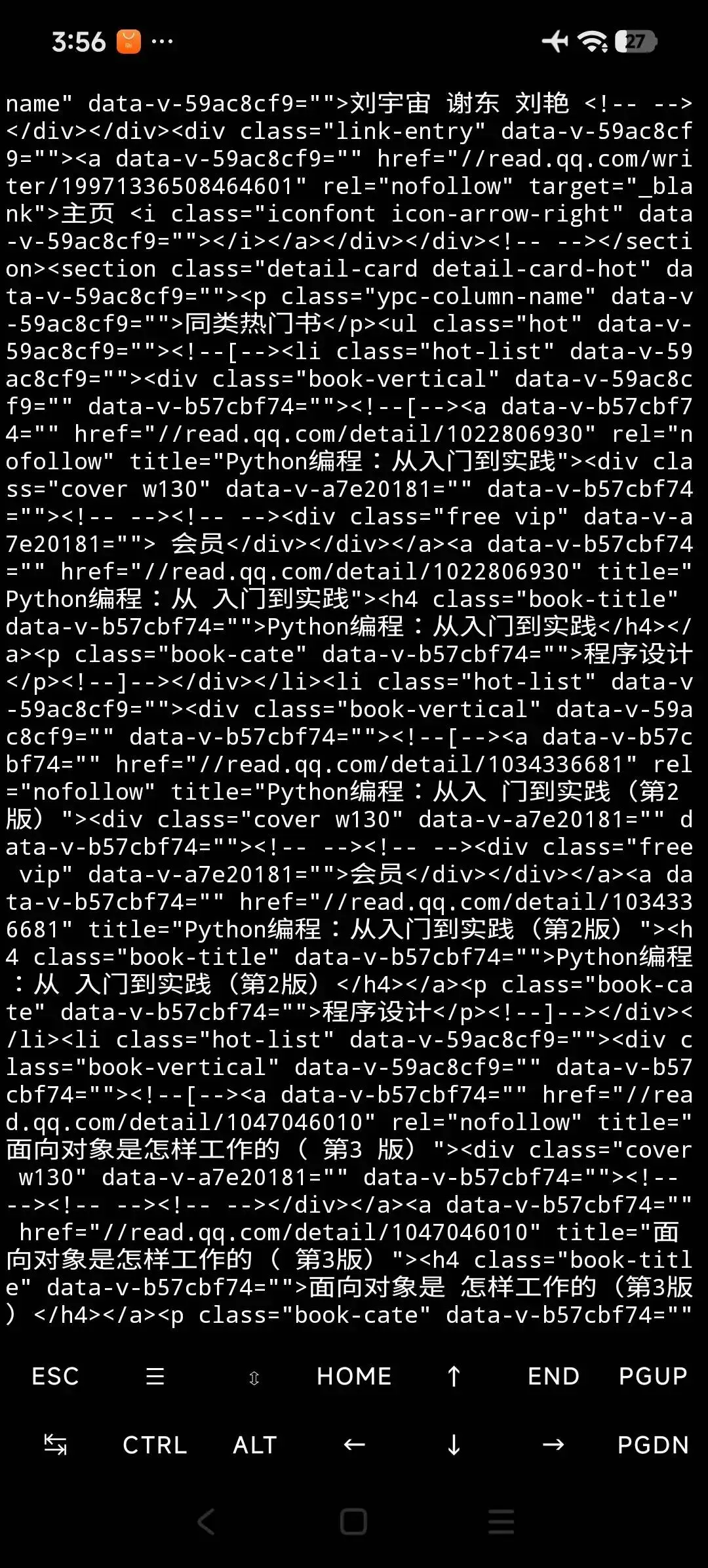
我們下面要用python將處理
一.用bs4對它大卸八塊
找到大概的位置
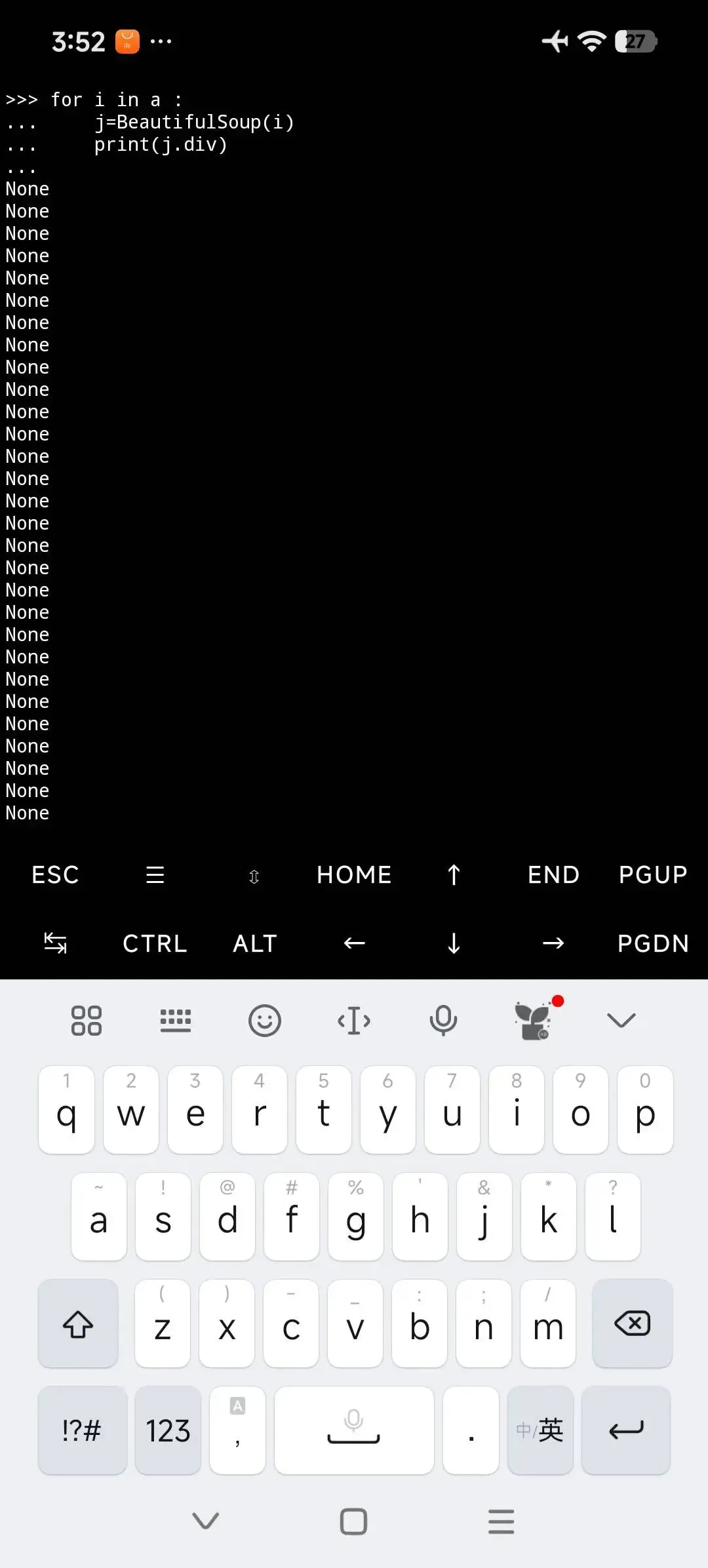
基中a=("??.html","r").readlines()
二.將這一部分用bs4再分割。
用soup.find_all("a")來得到a.標簽。
再分割
得到大概內容如下
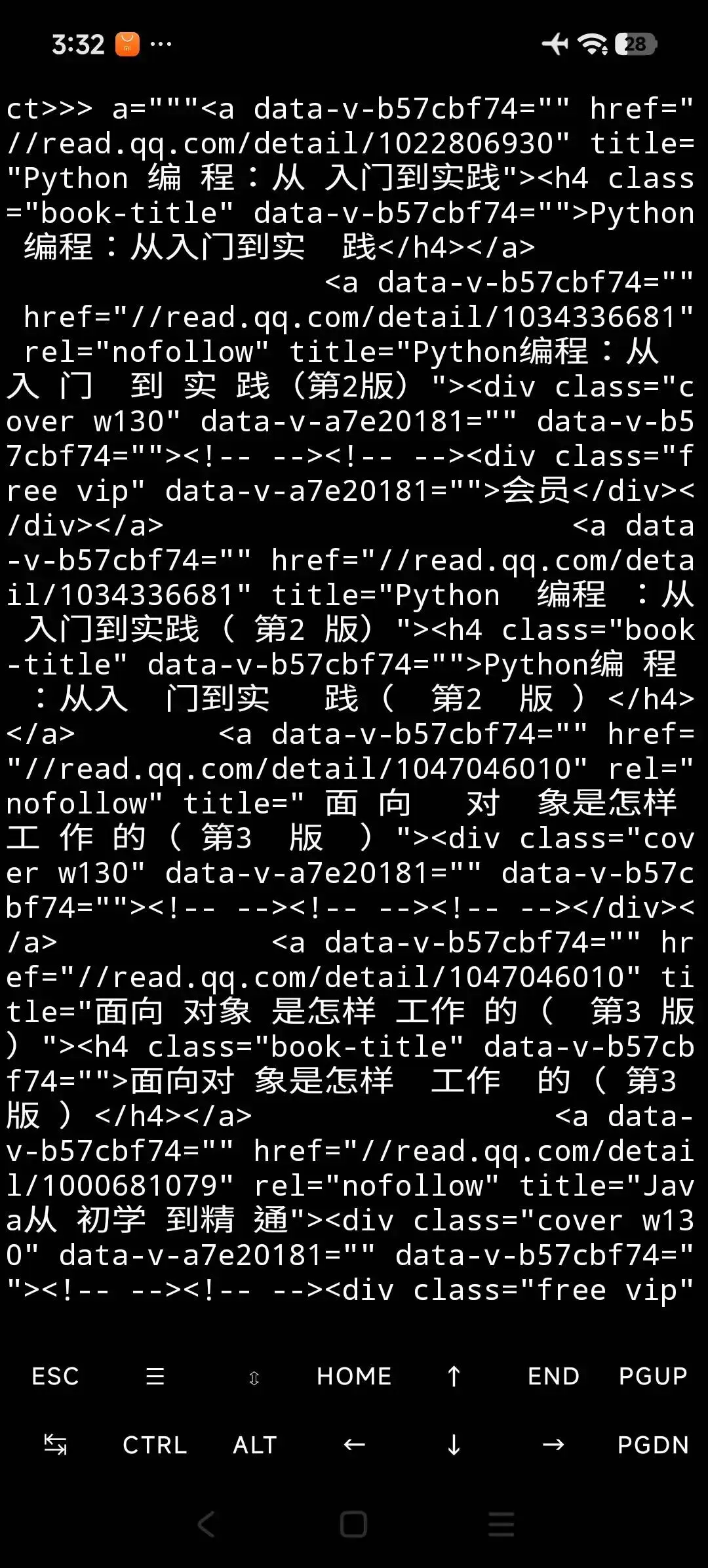
我們找到規律,兩個相同的href,對應一個h4的標簽,除了第一個。
剛好是15對
我們用正則中的re.findall來處理。
三.提取web地址
這裡條件這樣寫
rec='href="(.*?)"'
b1=re.findall(rec,a)
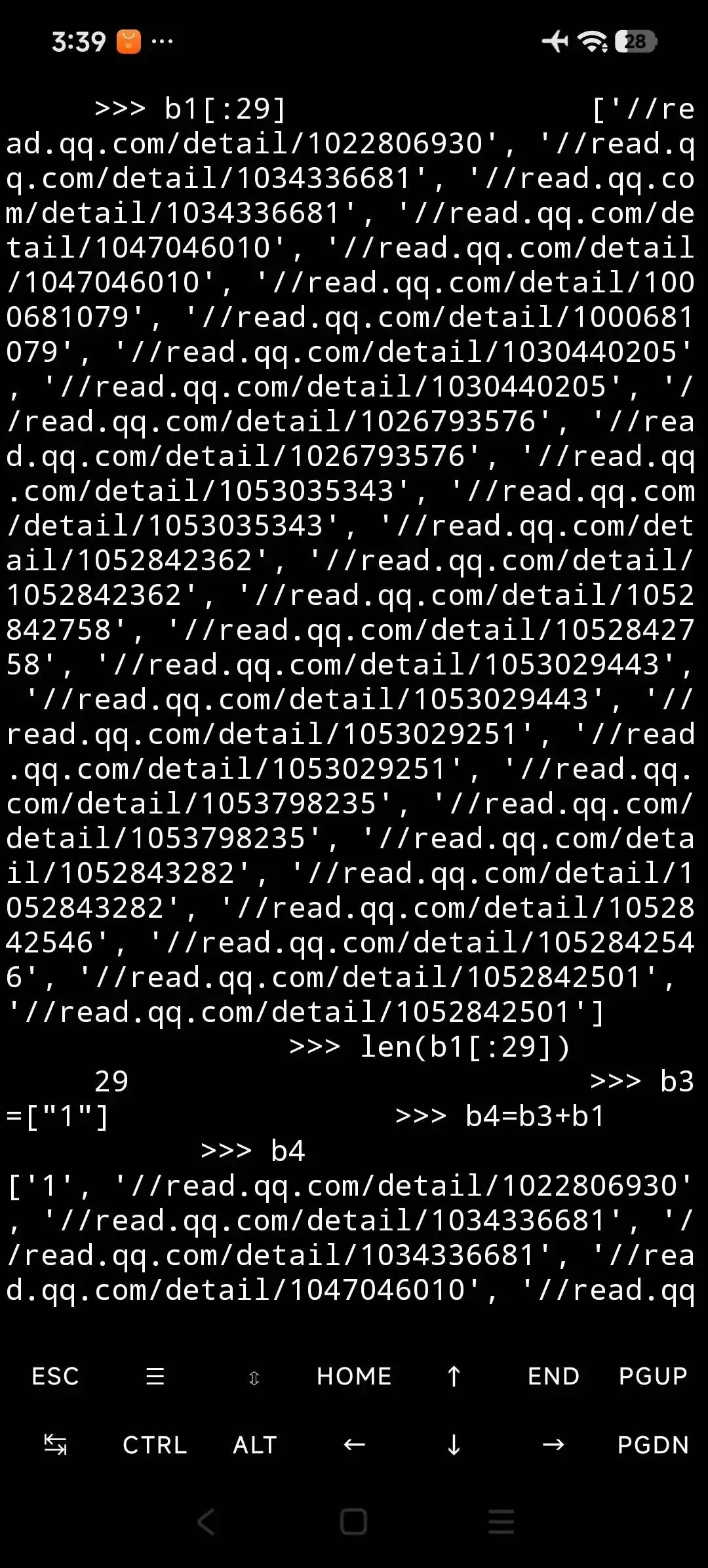
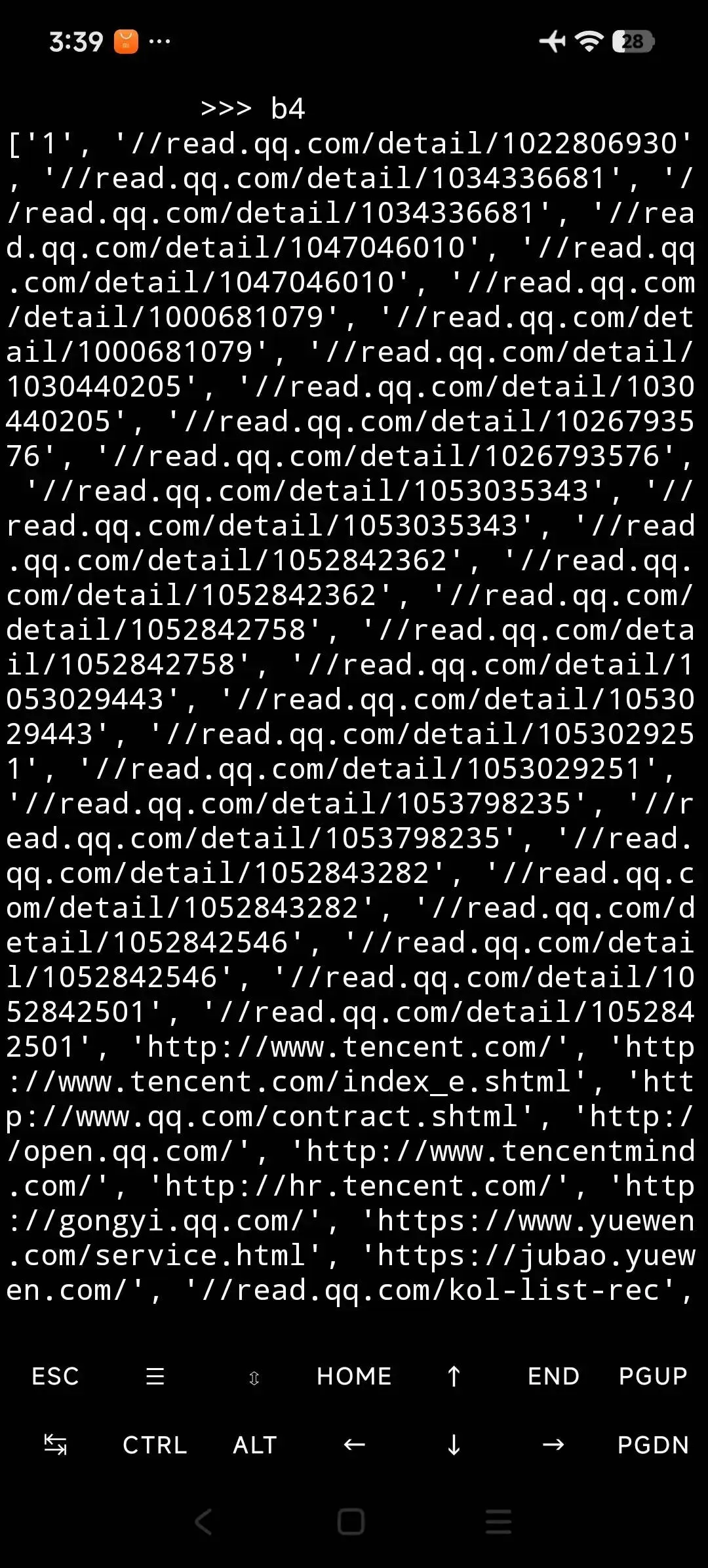
因為前面知道b4[0],單身的,我們把b前面又叉了一個元素"1"
四.提取h4
這裡條件這樣寫
rec='h4(.*?)/h4'
b2=re.findall(rec,a)
五.裝配
我們前面知道,兩個href,對應一個H4。
我們用

來得到b6
再下來這樣
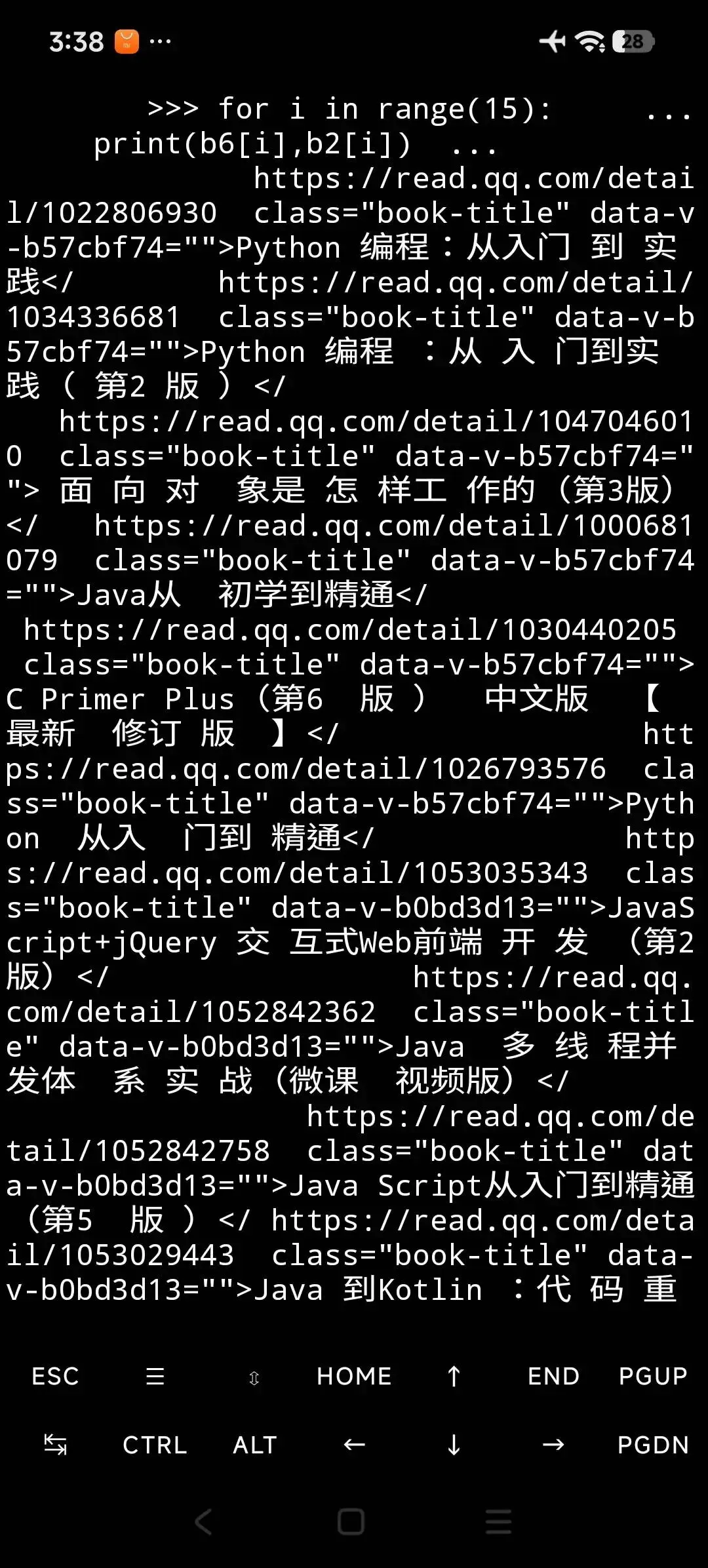
六.瀏覽

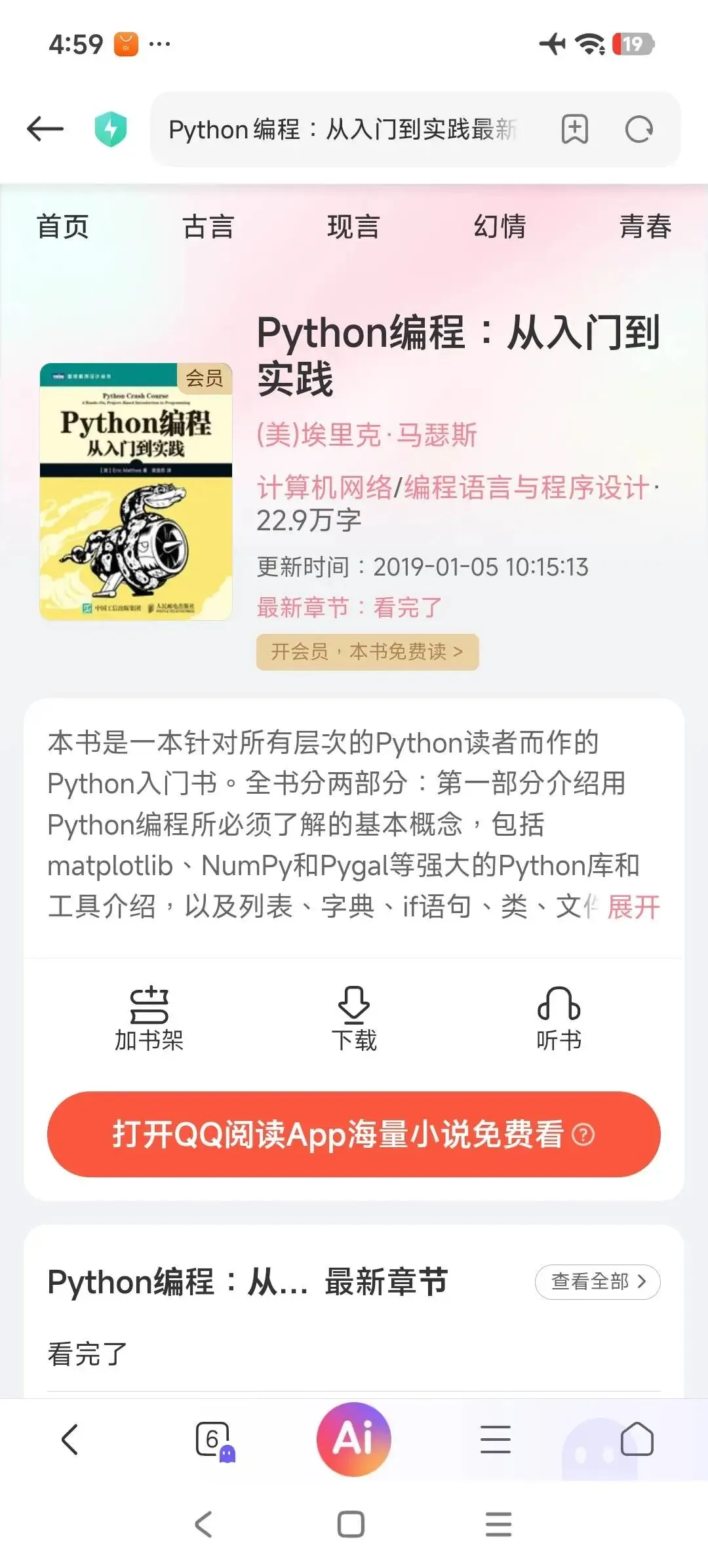
這樣操作下來,下次再看是不是很方便。頁面清爽了,人精神也變好了。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
