Linux磁盘IO工作原理
- 2026-07-06 04:32:40
在Linux系统中,磁盘IO是连接软件与硬件的关键桥梁,也是系统性能的核心瓶颈点之一。无论是日常的文件读写、数据库存储,还是大数据处理,背后都离不开磁盘IO的支撑。很多时候,系统卡顿、应用响应缓慢,根源都出在磁盘IO上。本文将从底层原理出发,带你全面拆解Linux磁盘IO的工作机制,包括核心架构、关键组件、性能指标及观测方法,帮你彻底搞懂磁盘IO到底是如何工作的。
一、先明确:磁盘IO的核心基础
在深入原理之前,我们先厘清几个核心概念,避免后续理解出现偏差。首先,磁盘IO本质上是“应用程序向存储设备读取或写入数据”的过程,而Linux系统为了屏蔽不同硬件的差异、提升IO效率,设计了一套分层的IO架构。其次,我们常见的存储设备主要分为两类,它们的IO工作方式差异巨大,直接影响系统性能:
1. 两种核心存储设备:机械硬盘(HDD)与固态硬盘(SSD)
机械硬盘(HDD):由盘片和读写磁头组成,数据存储在盘片的环状磁道上。读写数据前,必须先移动磁头定位到目标磁道,再等待盘片旋转到对应位置——这个“寻道+旋转”的过程是HDD性能的主要瓶颈。因此,HDD对连续IO更友好(无需频繁移动磁头),而随机IO性能较差。其最小读写单位是“扇区”,通常为512字节。
固态硬盘(SSD):由固态电子元器件组成,无需磁头寻道和盘片旋转,因此无论是连续IO还是随机IO,性能都远超HDD。但SSD存在“先擦除再写入”的特性,随机读写会触发大量垃圾回收,导致其随机IO性能仍略逊于连续IO。SSD的最小读写单位是“页”,常见大小为4KB、8KB等。
需要注意的是,无论是HDD还是SSD,直接读写最小单位(扇区/页)效率都很低。因此,Linux文件系统会将连续的扇区或页组合成“逻辑块”(常见大小为4KB),以逻辑块作为数据管理的最小单元。
2. 块设备:Linux对磁盘的统一抽象
在Linux中,所有磁盘设备都被抽象为“块设备”——即按“块”为单位读写数据,且支持随机访问的设备。每个块设备都会被分配两个设备号:主设备号用于区分设备类型(比如SATA硬盘和IDE硬盘),次设备号用于标识同类设备中的具体个体(比如第一块SATA硬盘/dev/sda和第二块/dev/sdb)。
此外,磁盘接入系统后还有多种使用架构:可以直接划分为分区使用(如/dev/sda1);也可以组合成RAID阵列(提升性能或可靠性);还可以通过NFS、iSCSI等协议作为网络存储供多台机器共享。
二、核心架构:Linux磁盘IO的三层栈结构
Linux为了实现“应用程序与具体存储设备解耦”,设计了分层的IO栈架构,从上层到下层依次为:文件系统层、通用块层、设备层。每一层都有明确的职责,通过标准化接口协作,既保证了灵活性,又提升了IO效率。这个三层架构是理解磁盘IO工作原理的关键。
1. 上层:文件系统层——应用程序的“IO接口”
这一层是应用程序直接接触的层面,核心是“虚拟文件系统(VFS)+ 具体文件系统实现”。VFS定义了一套统一的文件操作接口(如open、read、write),让应用程序无需关注底层存储设备和文件系统的具体实现;而ext4、XFS、Btrfs等具体文件系统,则负责将应用的IO请求转换为对逻辑块的操作。
比如,当你执行cat test.txt命令时,应用程序首先通过VFS调用read接口,VFS再将请求转发给对应的文件系统(如ext4),文件系统根据自身的存储规则,找到test.txt对应的逻辑块,然后将请求传递给下一层。
2. 中层:通用块层——磁盘IO的“核心调度中心”
通用块层是Linux磁盘IO的核心,处在文件系统层和设备层之间,扮演着“翻译官”和“优化师”的双重角色。它的核心作用有两个:
第一,统一接口与设备抽象:向上为文件系统层提供标准的块设备访问接口,向下将各种异构的存储设备(HDD、SSD、RAID等)抽象为统一的块设备,屏蔽不同硬件的差异,让上层无需关注设备细节。
第二,IO请求优化:这是通用块层最关键的功能。文件系统层传递过来的IO请求可能是零散、无序的,通用块层会对这些请求进行“排队、重新排序、请求合并”,以提升磁盘读写效率。这个优化过程就是“IO调度”。
Linux内核支持三种主流IO调度算法,适用于不同场景:
kyber:Linux内核中为多队列块设备(blk-mq)设计的I/O调度器,于Linux 4.12版本合入主线。它通过基于令牌的机制和动态延迟调整,专门针对高速存储设备(如NVMe SSD)优化,旨在实现低延迟和高吞吐量之间的平衡; bfq:(Budget Fair Queueing,预算公平排队)是Linux内核中的一种I/O调度算法,于Linux 4.12版本引入,旨在取代CFQ调度器。它通过预算分配机制,在保证公平性的同时,实现高吞吐量和低延迟的平衡。 mq_deadLine:mq-deadline(多队列截止时间调度器)是Linux内核中为多队列块设备(blk-mq)重新实现的Deadline调度器,于Linux 4.12版本引入。它通过截止时间机制和请求排序,在保证低延迟的同时实现高吞吐量,特别适合混合读写负载和需要避免请求饥饿的场景。
3. 下层:设备层——IO请求的最终执行者
设备层由存储设备(HDD、SSD等)和对应的驱动程序组成,负责接收通用块层转发的IO请求,最终完成物理设备的读写操作。驱动程序的作用是将内核的标准化IO请求,转换为硬件能理解的信号(比如控制HDD磁头移动、SSD写入数据)。
总结一下IO栈的工作流程:应用程序通过文件系统层发起IO请求 → 通用块层对请求进行优化调度 → 设备层通过驱动程序执行物理IO操作 → 结果沿原路径返回给应用程序。
三、关键补充:缓存机制如何提升IO效率?
由于磁盘IO是系统中最慢的环节之一,Linux设计了多种缓存机制来减少对物理磁盘的直接访问,从而提升IO效率。这些缓存贯穿整个IO栈,是理解IO性能的重要知识点:
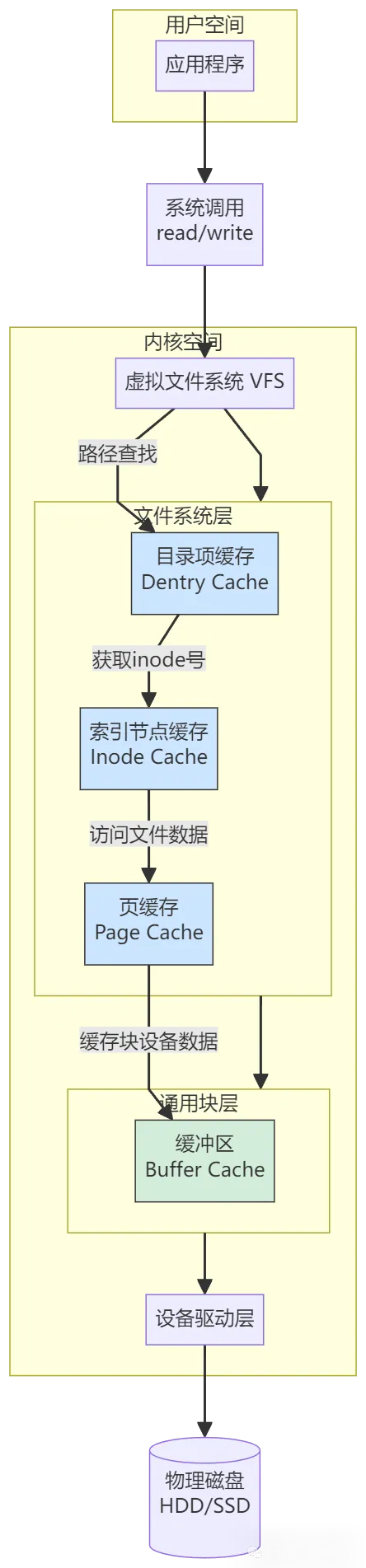
页缓存、inode缓存、dentry缓存:位于文件系统层,用于缓存文件数据、inode元数据(文件属性)、目录项(文件名与inode的映射)。应用程序读取文件时,优先从缓存中获取,未命中时才访问物理磁盘;
缓冲区:位于通用块层,用于缓存块设备的数据,减少对设备的重复读写。比如,多个小IO请求可以先在缓冲区合并,再一次性写入磁盘,提升效率。
这里需要注意:缓存虽好,但也会导致“应用程序读写大小”与“实际磁盘IO大小”不一致。比如,应用程序写入1KB数据,可能先被缓存,后续合并成4KB再写入磁盘,这也是后续性能观测中需要注意的点。
四、如何衡量磁盘IO性能?五大核心指标
理解了工作原理后,我们更关心“如何判断磁盘IO是否正常”。这就需要掌握衡量磁盘IO性能的五大核心指标,它们是分析IO瓶颈的基础:
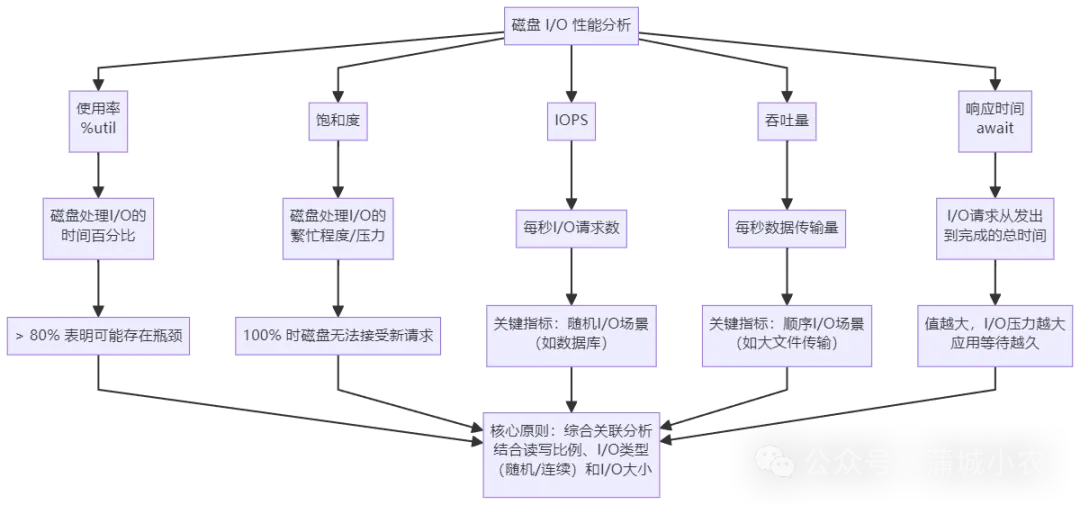
使用率(%util):磁盘处理IO的时间百分比。过高的使用率(比如超过80%)通常意味着IO存在瓶颈,但要注意:使用率只关注“是否有IO”,不关注IO大小,因此100%使用率并不代表磁盘无法接收新请求(可能存在并行IO); 饱和度:磁盘的繁忙程度,反映磁盘处理IO的压力。饱和度100%时,磁盘无法接收新的IO请求,是比使用率更精准的瓶颈判断指标,但无法直接观测,需结合其他指标综合评估; IOPS:每秒完成的IO请求数。适用于随机IO场景(如数据库、小文件存储),是评估这类场景性能的核心指标; 吞吐量:每秒读写的数据量(单位KB/s、MB/s等)。适用于连续IO场景(如多媒体文件、大数据批量处理),能直观反映磁盘的数据传输能力; 响应时间(await):IO请求从发出到完成的总时间(包括队列等待时间和设备处理时间)。响应时间越长,说明IO压力越大,应用程序需要等待更久。
重要提醒:不要孤立看待某一个指标。比如,同样是IOPS=1000,小请求(512B)对应的吞吐量可能只有500KB/s,而大请求(4KB)对应的吞吐量可能达到4MB/s。必须结合“读写比例、IO类型(随机/连续)、IO大小”综合分析。
五、实用工具:如何观测磁盘IO性能?
掌握了指标后,我们需要借助工具获取这些数据。下面介绍3个最常用的Linux磁盘IO观测工具,覆盖“磁盘整体IO”和“进程级IO”两种核心场景:
1. iostat:磁盘整体IO观测神器
iostat是最基础也最常用的工具,用于查看每块磁盘的整体IO情况,数据来源于/proc/diskstats。核心用法:iostat -d -x 1,其中“-d”表示只显示磁盘IO数据,“-x”表示显示详细指标,“1”表示每秒刷新一次。
关键输出指标解读(对应核心性能指标):
2. pidstat:进程级IO观测工具
iostat只能查看磁盘整体情况,无法定位到具体哪个进程在占用IO。pidstat可以弥补这个不足,通过pidstat -d 1命令(“-d”表示显示IO相关数据),可以实时查看每个进程的IO情况,包括:
kB_rd/s:进程每秒读取的数据量; kB_wr/s:进程每秒写入的数据量; iodelay:进程等待块IO完成的时间(时钟周期); Command:对应的进程名称。
3. iotop:按IO大小排序的进程观测工具
iotop类似于“IO版top”,可以按IO大小对进程排序,快速找到IO占用最高的“元凶”。直接执行iotop即可,核心输出包括:
Total DISK READ/WRITE:所有进程的总读写大小; Actual DISK READ/WRITE:物理磁盘的真实读写大小(因缓存等因素,可能与总读写大小不一致); DISK READ/WRITE:每个进程的每秒读写大小; IO>:进程等待IO的时间百分比。
六、实战思路:如何排查磁盘IO瓶颈?
结合前面的原理和工具,我们可以总结出一套简单的IO瓶颈排查思路:
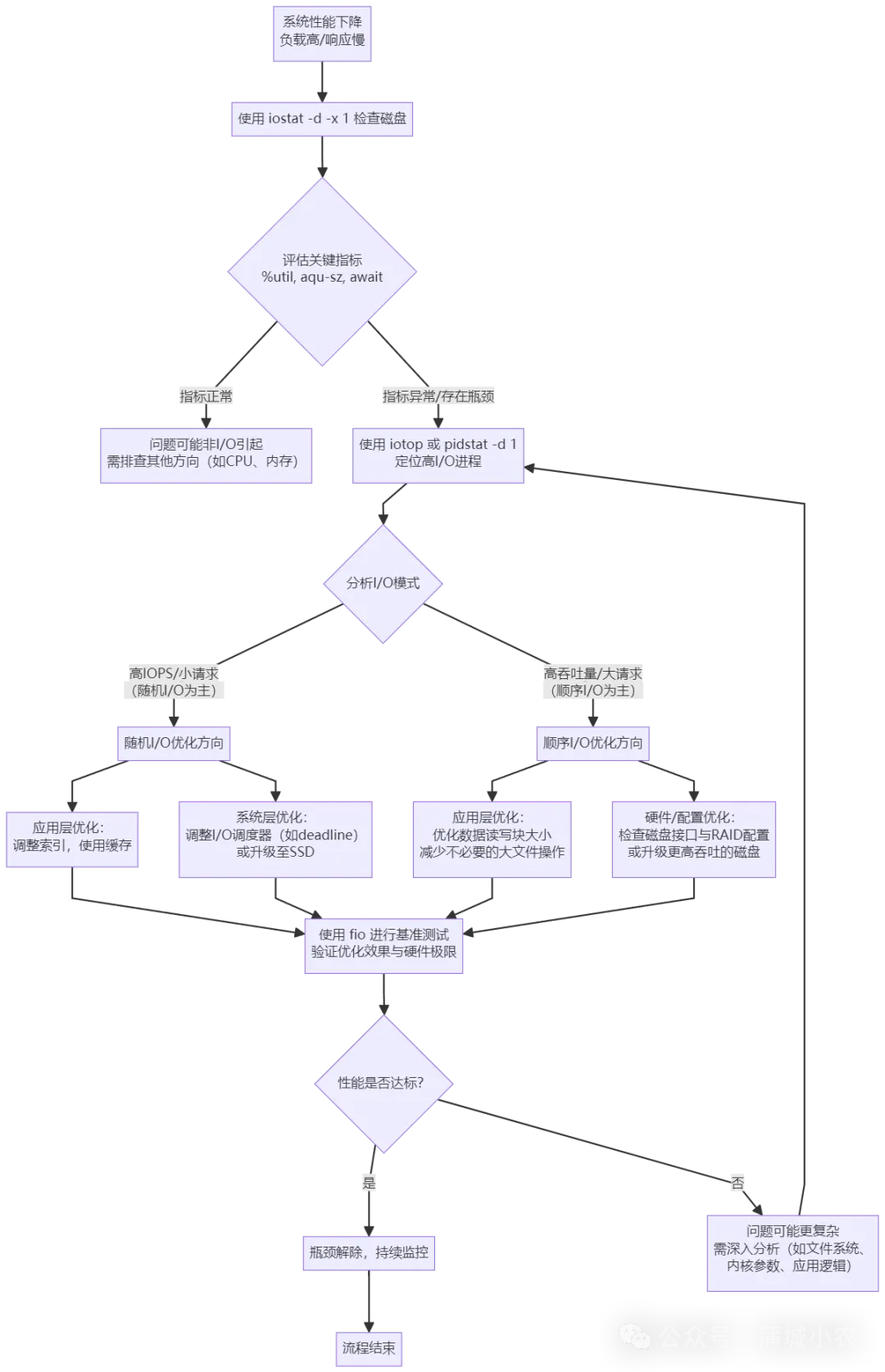
用 iostat -d -x 1查看磁盘整体IO:若%util过高、aqu-sz过大、await过长,说明磁盘存在IO瓶颈;用 iotop或pidstat -d 1定位高IO进程:找到占用IO最多的进程,判断是应用程序(如数据库)还是系统进程;结合IO类型分析:若IOPS高、请求小,说明是随机IO(需优化IO调度算法如DeadLine,或升级SSD);若吞吐量低、请求大,说明是连续IO(需检查磁盘接口、RAID配置); 基准测试验证:用fio工具测试磁盘的极限IOPS、吞吐量等指标,对比实际观测值,判断磁盘是否已达性能上限。
七、总结
Linux磁盘IO的工作原理可以总结为“三层栈架构+缓存优化”:应用程序通过文件系统层发起请求,通用块层进行调度优化,设备层完成物理IO;同时,系统通过多种缓存机制减少物理磁盘访问,提升效率。而排查IO瓶颈的核心,是掌握“使用率、饱和度、IOPS、吞吐量、响应时间”五大指标,借助iostat、pidstat、iotop等工具,从“整体磁盘”到“具体进程”逐步定位问题。
理解磁盘IO的工作原理,不仅能帮助我们快速排查性能问题,还能在系统选型(如HDD vs SSD)、应用优化(如减少随机IO)时做出更合理的决策。希望本文能帮你打通Linux磁盘IO的知识脉络,下次遇到IO相关的问题时,能从容应对!
如果你的工作中遇到过磁盘IO瓶颈,欢迎在评论区分享你的排查经验,我们一起交流学习~
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python:内置类型也是类对象
- ReaxFF-nn 代码:基于GULP/LAMMPS平台的反应式机器学习势函数及其在碳纳米结构热导率计算中的应用
- 5python之列表搜索及获取标签处理
- AI开发实战:1、手摸手教你一行代码不写,全程AI写个小程序——前端布局
- Karpathy:我现在用英语编程,这是20年来最大的变化
- 长牛代码 | 盘后速递:春燥第二波继续要看明天收周线、月线的情况——2026年1月29日盘面全解析与策略
- 用 Python 构建 GJR-GARCH 波动率择时策略:让你的投资更稳健
- 【匠心絮语】匠心初绽:从代码行间到接线端子
- 全环境立德树人 ‖ 河西学校幼儿园乐高编程课堂纪实
- 从“凭感觉出活”到“按规范量产”:AI编程从vibe到spec的演进逻辑
